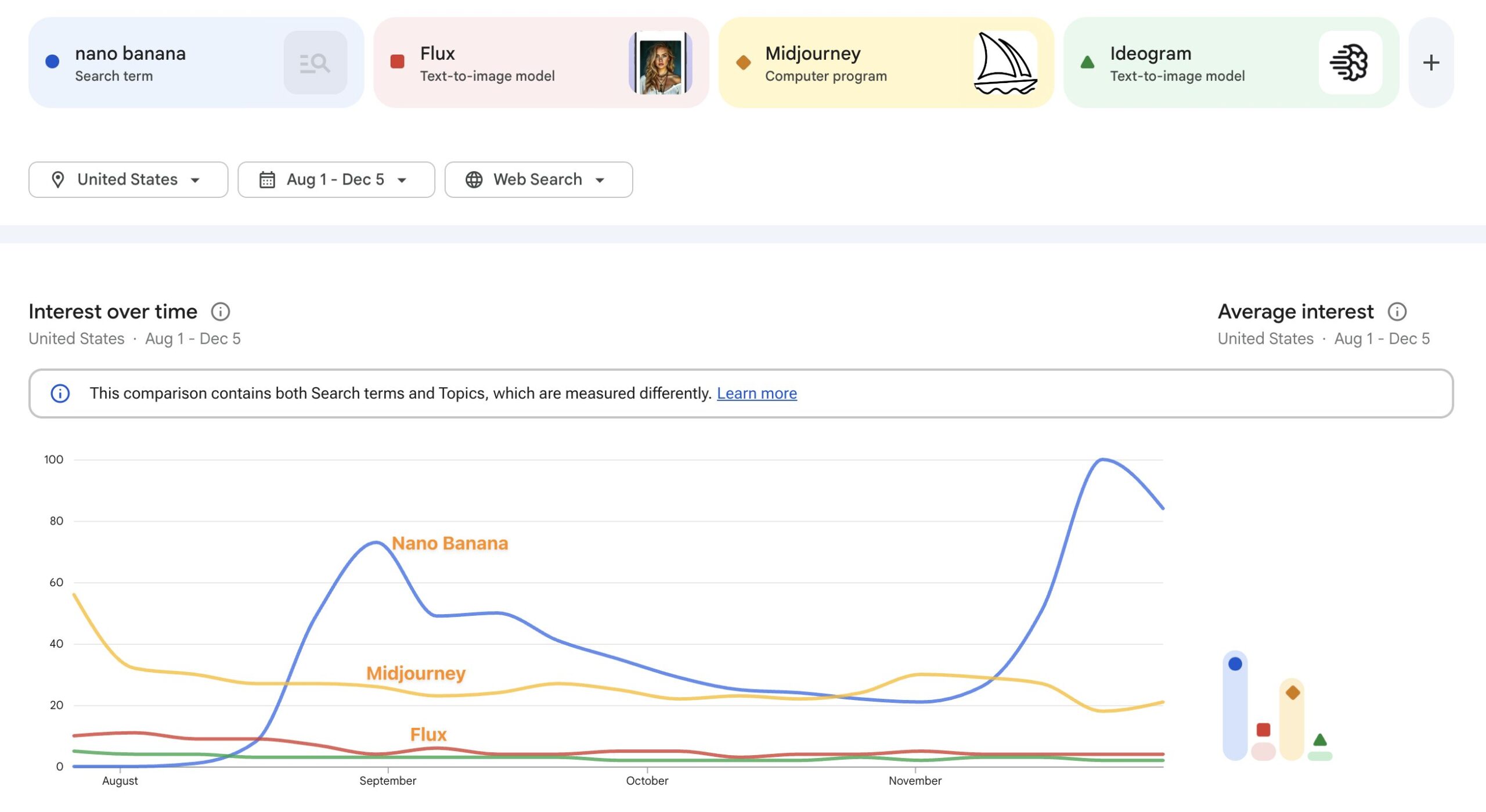
This season my alma mater has been rolling out sport-specific versions of the classic leprechaun logo, and when the new basketball version dropped today, I decided to have a little fun seeing how well Nano Banana could riff on the theme.
My quick take: It’s pretty great, though applying sequential turns may cause the style to drift farther from the original (more testing needed).
I dig it. Just for fun, I asked Google’s @NanoBanana to create more variations for other sports: pic.twitter.com/i3CBTr8bpp
— John Nack (@jnack) December 9, 2025