I’m excited to learn more about GenLit, about which its creators say,
Given a single image and the 5D lighting signal, GenLit creates a video of a moving light source that is inside the scene. It moves around and behind scene objects, producing effects such as shading, cast shadows, secularities, and interreflections with a realism that is hard to obtain with traditional inverse rendering methods.
Video diffusion models have strong implicit representations of 3D shape, material, and lighting, but controlling them with language is cumbersome, and control is critical for artists and animators.
I stumbled across some compelling teaser videos for this product, about which only a bit of info seems to be public:
A Photoshop plugin that brings truly photorealistic, prompt-free relighting into existing workflows. Instead of describing what you want in text, control lighting through visual adjustments. Change direction, intensity, and mood with precision… Modify lighting while preserving the structure and integrity of the original image. No more destructive edits or starting over.
Identity preservation—that is, exactly maintaining the shape & character of faces, products, and other objects—has been the lingering downfall of generative approaches to date, so I’m eager to take this for a spin & see how it compares to other approaches.
The moment I switched on gravity was the moment everything changed.
Lines I had just drawn started to fall, swing, and collide like they were suddenly alive inside my room. A simple sketch became an object with weight. A doodle turned into something that could react back. It is one of those Vision Pro moments where you catch yourself smiling because it feels playful in a way you do not see coming.
Of course, Old Man Nack™ feels like being a little cautious here: Ten years ago (!) my kids were playing in Adobe’s long-deceased Project Dali…
…and five years ago Google bailed on the excellent Tilt Brush 3D painting app it acquired. ¯\_(ツ)_/¯
And yet, and yet, and yet… I Want To Believe. As I wrote back in 2015,
I always dreamed of giving Photoshop this kind of expressive painting power; hence my long & ultimately fruitless endeavor to incorporate Flash or HTML/WebGL as a layer type. Ah well. It all reminds me of this great old-ish commercial:
So, in the world of AI, and with spatial computing staying a dead parrot (just resting & pining for the fjords!), who knows what dreams may yet come?
Just yesterday I was chatting with a new friend from Punjab about having worked with a coincidentally named pair of teammates at Google—Kieran Murphy & Kiran Murthy. I love getting name-based insights into culture & history, and having met cool folks in Zimbabwe last year, this piece from 99% Invisible is 1000% up my alley.
This stuff of course looks amazing—but not wholly new. Krea debuted realtime generation more than two years ago, leading to cool integrations with various apps, including Photoshop:
My photoshop is more fun than yours With a bit of help from Krea ai.
It’s a crazy feeling to see brushstrokes transformed like this in realtime.. And the feeling of control is magnitudes better than with text prompts.#ai#artpic.twitter.com/Rd8zSxGfqD
The interactive paradigm is brilliant, but comparatively low quality has always kept this approach from wide adoption. Compare these high-FPS renders to ChatGPT’s Studio Ghibli moment: the latter could require multiple minutes to produce a single image, but almost no one mentioned its slowness. “Fast is good, but good is better.”
I hope that Krea (and others) are quietly beavering away on a hybrid approach that combines this sort of addictive interactivity with a slower but higher-quality render (think realtime output fed into Nano Banana or similar for a final pass). I’d love to compare the results against unguided renders from the slower models. Perhaps we shall see!
Apple’s new 2D-to-3D tech looks like another great step in creating editable representations of the world that capture not just what a camera sensor saw, but what we humans would experience in real life:
Excited to release our first public AI model web app, powered by Apple’s open-source ML SHARP.
Turn a single image into a navigable 3D Gaussian Splat with depth understanding in seconds.
Almost exactly 19 years ago (!), I blogged about some eye-popping tech that promised interactive control over portrait lighting:
I was of course incredibly eager to get it into Photoshop—but alas, it’d take years to iron out the details. Numerous projects have reached the market (see the whole big category here I’ve devoted to them), and now with “Light Touch,” Adobe is promising even more impressive & intuitive control:
This generative AI tool lets you reshape light sources after capture — turning day to night, adding drama, or adjusting focus and emotion without reshoots. It’s like having total control over the sun and studio lights, all in post.
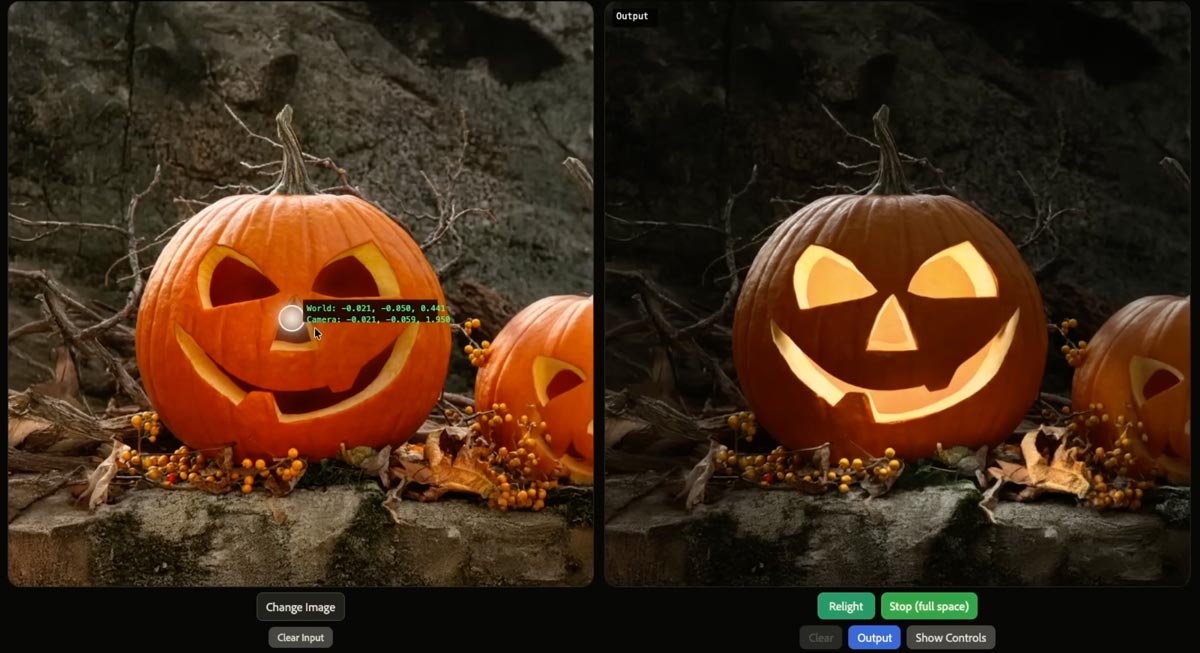
Check it out:
If nothing else, make sure you see the pumpkin part, which rightfully causes the audience to go nuts. 🙂
Less prompting, more direct physicality: that’s what we need to see in Photoshop & beyond.
As an example, developer apolinario writes, “I’ve built a custom camera control @gradio component for camera control LoRAs for image models Here’s a demo of @fal’s Qwen-Image-Edit-2511-Multiple-Angles-LoRA using the interactive camera component”:
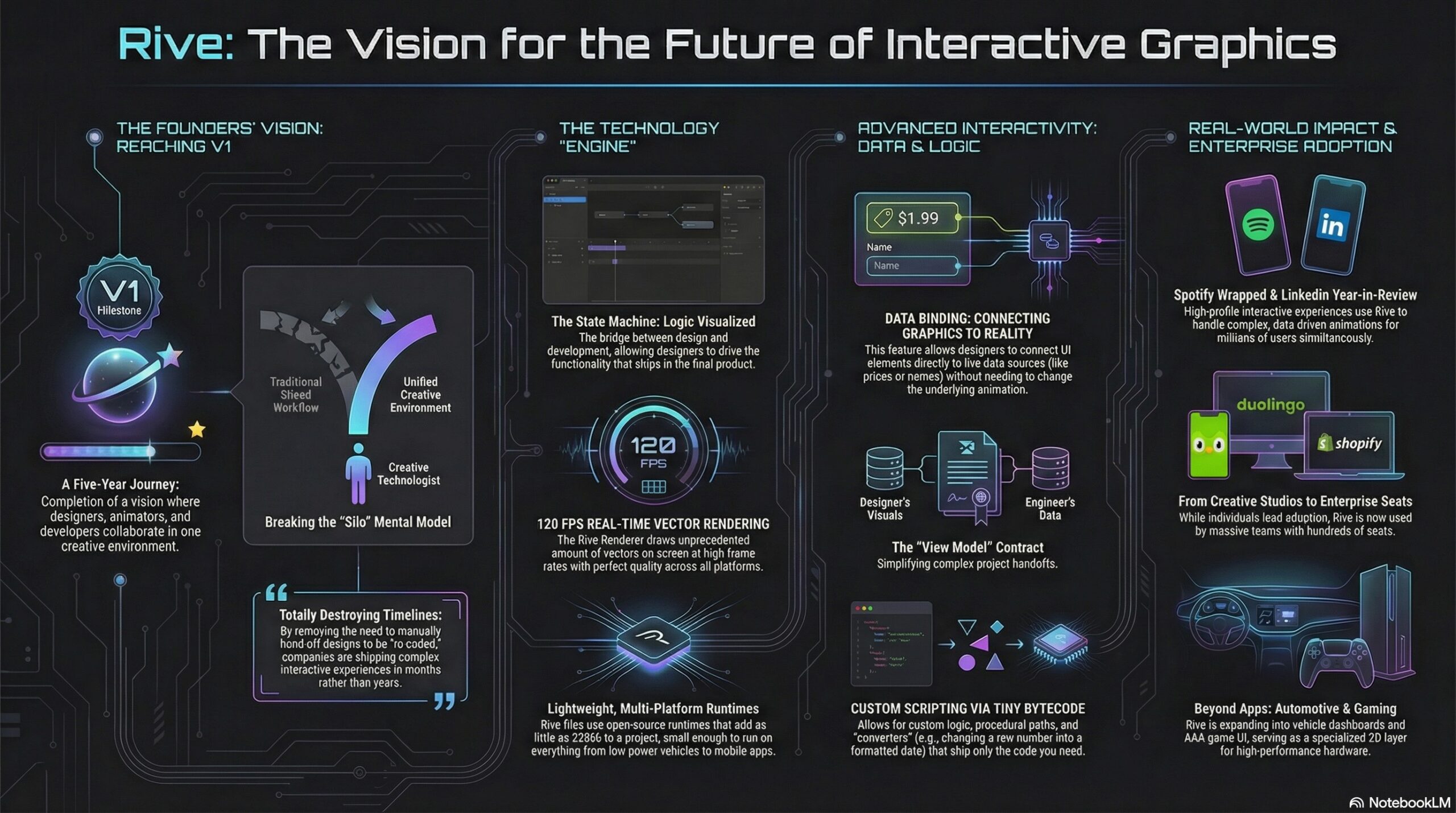
Having gotten my start in Flash 2.0 (!), and having joined Adobe in 2000 specifically to make a Flash/SVG authoring tool that didn’t make me want to walk into the ocean, I felt my cold, ancient Grinch-heart grow three sizes listening to Guido and Luigi Rosso—the brother founders behind Rive—on the School of Motion podcast:
[They] dig into what makes this platform different, where it’s headed, and why teams at Spotify, Duolingo, and LinkedIn are building entire interactive experiences with it!
Here’s a NotebookLM-made visualization of the key ideas:
Table of contents:
Reflecting on 2025: A Year of Milestones 00:24 The Challenges of a Three-Sided Marketplace 02:58 Adoption Across Designers, Developers, and Companies 04:11 The Evolution of Design and Development Collaboration 05:46 The Power of Data Binding and Scripting 07:01 Rive’s Impact on Product Teams and Large Enterprises 09:18 The Future of Interactive Experiences with Rive 12:36 Understanding Rive’s Mental Model and Scripting 24:32 Comparing Rive’s Scripting to After Effects and Flash The Vision for Rive in Game Development 31:30 Real-Time Data Integration and Future Possibilities 40:26 Spotify Wrapped: A Showcase of Rive’s Potential 42:08 Breaking Down Complex Experiences 46:18 Creative Technologists and Their Impact 51:07 The Future of Rive: 3D and Beyond 59:30 Opportunities for Motion Designers with Rive 1:11:38
As AI continues to infuse itself more deeply into our world, I feel like I’ll often think of Paul Graham’s observation here:
Paul Graham on why you shouldn’t write with AI:
“In preindustrial times most people’s jobs made them strong. Now if you want to be strong, you work out. So there are still strong people, but only those who choose to be. It will be the same with writing. There will… pic.twitter.com/RWGZeJetUp
I initially mistook this tech as text->layers, but it’s actually image->layers. Having said that, if it works well, it might be functionally similar to direct layer output. I need to take it for a spin!
We’re finally getting layers in AI images.
The new Qwen Image Layered LoRA allows you to decompose any image into layers – which means you can move, resize, or replace an object / background.
“It’s not that you’re not good enough, it’s just that we can make you better.”
So sang Tears for Fears, and the line came to mind as the recently announced PhotaLabs promised to show “your reality, but made more magical.” That is, they create the shots you just missed, or wish you’d have taken:
Honestly, my first reaction was “ick.” I know that human memory is famously untrustworthy, and photos can manipulate it—not even through editing, but just through selective capture & curation. Even so, this kind of retroactive capture seems potentially deranging. Here’s the date you wish you’d gone on; here’s the college experience you wish you’d had.
I’m reminded of the Nathaniel Hawthorne quote featured on the Sopranos:
No man for any considerable period can wear one face to himself, and another to the multitude, without finally getting bewildered as to which may be the true.
Like, at what point did you take these awkward sibling portraits…?
We all need an awkward ’90s holiday photoshoot with our siblings.
If you missed the boat (like I did), you’re in luck – I wrote some prompts you can use with Nano Banana Pro
Upload a photo of each person and then use the following:
And, hey, darn if I can resist the devil’s candy: I wasn’t able to capture a shot of my sons together with their dates, so off I went to a combo of Gemini & Ideogram. I honestly kinda love the results, and so down the cognitive rabbit hole I slide… ¯\_(ツ)_/¯
Of course, depending on how far all this goes, the following tweet might prove to be prophetic:
Modern day horror story where you look though the photo albums of you as a kid and realize all the pictures have this symbol in the corner pic.twitter.com/dHnUrUJs0r