Heh—it’s fun to see the fruits of my former team’s efforts going to fun use: Google’s open-source MediaPipe framework enables body tracking, among many other things:
i made tetris but the board and pieces are attached to your body and it’s quite tiring to play pic.twitter.com/yEoA49igpX
I’m intrigued but not quite sure how to feel about this. Precisely tracking groups of fast-moving human bodies & producing lifelike 3D copies in realtime is obviously a stunning technical coup—but is watching the results something people will prefer to high-def video of the real individuals & all their expressive nuances? I have no idea, but I’d like to know more.
You’ll scream, you’ll cry, promises designer Dave Werner—and maybe not due just to “my questionable dance moves.”
Live-perform 2D character animation using your body. Powered by Adobe Sensei, Body Tracker automatically detects human body movement using a web cam and applies it to your character in real time to create animation. For example, you can track your arms, torso, and legs automatically. View the full release notes.
As I’m on a kick sharing recent work from Ira Kemelmacher-Shlizerman & team, here’s another banger:
Given an “in-the-wild” video, we train a deep network with the video frames to produce an animatable human representation.
This can be rendered from any camera view in any body pose, enabling applications such as motion re-targeting and bullet-time rendering without the need for rigged 3D meshes.
I look forward (?) to the not-so-distant day when a 3D-extracted Trevor Lawrence hucks a touchdown to Cleatus the Fox Sports Robot. Grand slam!!
“VOGUE: Try-On by StyleGAN,” from my former Google colleague Ira Kemelmacher-Shlizerman & her team, promises to synthesize photorealistic clothing & automatically apply it to a range of body shapes (leveraging the same StyleGAN foundation that my new teammates are using to build images via text):
No markers, no mocap cameras, no suit, no keyframing. This take uses 3 DSLR cameras, though, and pretty far from being real-time. […]
Under the hood, it uses #OpenPose ML-network for 2d tracking of joints on each camera, and then custom Houdini setup for triangulating the results into 3d, stabilizing it and driving the rig (volumes, CHOPs, #kinefx, FEM – you name it 🙂
From sign language to sports training to AR effects, tracking the human body unlocks some amazing possibilities, and my Google Research teammates are delivering great new tools:
We are excited to announce MediaPipe Holistic, […] a new pipeline with optimized pose, face and hand components that each run in real-time, with minimum memory transfer between their inference backends, and added support for interchangeability of the three components, depending on the quality/speed tradeoffs.
When including all three components, MediaPipe Holistic provides a unified topology for a groundbreaking 540+ keypoints (33 pose, 21 per-hand and 468 facial landmarks) and achieves near real-time performance on mobile devices. MediaPipe Holistic is being released as part of MediaPipe and is available on-device for mobile (Android, iOS) and desktop. We are also introducing MediaPipe’s new ready-to-use APIs for research (Python) and web (JavaScript) to ease access to the technology.
Call it AI, ML, FM (F’ing Magic), whatever: tech like this warms the heart and can free body & soul. Google’s Project Guideline helps people with impaired vision navigate the world on their own, independently & at speed. Runner & CEO Thomas Panek, who is blind, writes,
In the fall of 2019, I asked that question to a group of designers and technologists at a Google hackathon. I wasn’t anticipating much more than an interesting conversation, but by the end of the day they’d built a rough demo […].
I’d wear a phone on a waistband, and bone-conducting headphones. The phone’s camera would look for a physical guideline on the ground and send audio signals depending on my position. If I drifted to the left of the line, the sound would get louder and more dissonant in my left ear. If I drifted to the right, the same thing would happen, but in my right ear. Within a few months, we were ready to test it on an indoor oval track. […] It was the first unguided mile I had run in decades.
Check out the journey. (Side note: how great is “Blaze” as a name for a speedy canine running companion? ☺️)
There’s no way the title can do this one justice, so just watch as this ML-based technique identifies moving humans (including their reflections!), then segments them out to enable individual manipulation—including syncing up their motions and even removing people wholesale:
https://youtu.be/2pWK0arWAmU
Here’s the vid directly from the research team, which includes longtime Adobe vet David Salesin:
Brief, beautiful choreography intertwines with particle effects in Barnaby Roper’s collaboration with dancer Kendi Jones, memorializing Elizabeth Eckford’s historic walk to school in 1957:
Awesome work by the team. Come grab a copy & build something great!
The ML Kit Pose Detection API is a lightweight versatile solution for app developers to detect the pose of a subject’s body in real time from a continuous video or static image. A pose describes the body’s position at one moment in time with a set of x,y skeletal landmark points. The landmarks correspond to different body parts such as the shoulders and hips. The relative positions of landmarks can be used to distinguish one pose from another.
My old teammates keep slapping out the bangers, releasing machine-learning tech to help build apps that key off the human form.
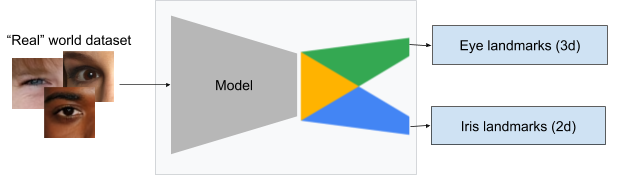
First up is Media Pipe Iris, enabling depth estimation for faces without fancy (iPhone X-/Pixel 4-style) hardware, and that in turn opens up access to accurate virtual try-on for glasses, hats, etc.:
The model enables cool tricks like realtime eye recoloring:
I always find it interesting to glimpse the work that goes in behind the scenes. For example:
To train the model from the cropped eye region, we manually annotated ~50k images, representing a variety of illumination conditions and head poses from geographically diverse regions, as shown below.
The team has followed up this release with MediaPipe BlazePose, which is in testing now & planned for release via the cross-platform ML Kit soon:
Our approach provides human pose tracking by employing machine learning (ML) to infer 33, 2D landmarks of a body from a single frame. In contrast to current pose models based on the standard COCO topology, BlazePose accurately localizes more keypoints, making it uniquely suited for fitness applications…
If one leverages GPU inference, BlazePose achieves super-real-time performance, enabling it to run subsequent ML models, like face or hand tracking.
Now I can’t wait for apps to help my long-suffering CrossFit coaches actually quantify the crappiness of my form. Thanks, team! 😛
It may seem like a small thing, but I’m happy to say that my previous team’s work on realtime human segmentation + realtime browser-based machine learning will be coming to Google Meet soon, powering virtual backgrounds:
Since making Google Meet premium video meetings free and available to everyone, we’ve continued to accelerate the development of new features… In the coming months, we’ll make it easy to blur out your background, or replace it with an image of your choosing so you can keep your team’s focus solely on you.
This is kinda inside-baseball, but I’m really happy that friends from my previous team will now have their work distributed on hundreds of millions, if not billions, of devices:
[A] face contours model — which can detect over 100 points in and around a user’s face and overlay masks and beautification elements atop them — has been added to the list of APIs shipped through Google Play Services…
Lastly, two new APIs are now available as part of the ML Kit early access program: entity extraction and pose detection… Pose detection supports 33 skeletal points like hands and feet tracking.
Let’s see what rad stuff the world can build with these foundational components. Here’s an example of folks putting an earlier version to use, and you can find a ton more in my Body Tracking category:
Inspired by her hometown in Congo, Anifa was intentional about shedding light on issues facing the Central African country with a short documentary at the start of the show. From mineral site conditions to the women and children who suffer as a result of these issues, Anifa’s mission was to educate before debuting any clothes. “Serving was a big part of who I am, and what I want to do,” she said in the short documentary.
Heh—here’s a super fun application of body tracking tech (see whole category here for previous news) that shows off how folks have been working to redefine what’s possible with. realtime machine learning on the Web (!):
One’s differing physical abilities shouldn’t stand in the way of drawing & making music. Body-tracking tech from my teammates George & Tyler (see previous) is just one of the new Web-based experiments in Creatability. Check it out:
Creatability is a set of experiments made in collaboration with creators and allies in the accessibility community. They explore how creative tools – drawing, music, and more – can be made more accessible using web and AI technology. They’re just a start. We’re sharing open-source code and tutorials for others to make their own projects.
This 💩 is 🍌🍌🍌, B-A-N-A-N-A-S: This Video-to-Video Synthesis tech apparently can take in one dance performance & apply it to a recording of another person to make her match the moves:
It can even semantically replace entire sections of a scene—e.g. backgrounds in a street scene:
Now please excuse me while I lie down for a bit, as my brain is broken.
Apropos of Google’s Move Mirror project (mentioned last week), here’s a similar idea:
Kinemetagraph reflects the bodily movement of the visitor in real time with a matching pose from the history of Hollywood cinema. To achieve this, it correlates live motion capture data using Kinect-based “skeleton tracking” to an open-source computer vision research dataset of 20,000 Hollywood film stills with included character pose metadata for each image.
The notable thing, I think, is that what required a dedicated hardware sensor a couple of years ago can now be done plug-in-free using just a browser and webcam. Progress!
Unleash the dank emotes! My teammates George & Tyler (see previous) are back at it running machine learning in your browser, this time to get you off the couch with the playful Move Mirror:
Move Mirror takes the input from your camera feed and maps it to a database of more than 80,000 images to find the best match. It’s powered by Tensorflow.js—a library that runs machine learning models on-device, in your browser—which means the pose estimation happens directly in the browser, and your images are not being stored or sent to a server. For a deep dive into how we built this experiment, check out this Medium post.
My teammates George & Tyler have been collaborating with creative technologist Dan Oved to enable realtime human pose estimation in Web browsers via the open-source Tensorflow.js (the same tech behind the aforementioned Emoji Scavenger Hunt). You can try it out here and read about the implementation details over on Medium.
Ok, and why is this exciting to begin with? Pose estimation has many uses, from interactive installations that react to the body to augmented reality, animation, fitness uses, and more. […]
With PoseNet running on TensorFlow.js anyone with a decent webcam-equipped desktop or phone can experience this technology right from within a web browser. And since we’ve open sourced the model, JavaScript developers can tinker and use this technology with just a few lines of code. What’s more, this can actually help preserve user privacy. Since PoseNet on TensorFlow.js runs in the browser, no pose data ever leaves a user’s computer.
“Teaching Google Photoshop” has been my working mantra here—i.e. getting computers to see like artists & wield their tools. A lot of that hinges upon understanding the shape & movements of the human body. Along those lines, my Google Research teammates Tyler Zhu, George Papandreou, and co. are doing cool work to estimate human poses in video. Check out the demo below, and see their poster and paper for more details.