Me: “What is the most ridiculous question I asked this year?”
Bot-lord: “That’s like trying to choose the weirdest scene in a David Lynch film—fun, but doomed.”
Me: “What is the most ridiculous question I asked this year?”
Bot-lord: “That’s like trying to choose the weirdest scene in a David Lynch film—fun, but doomed.”
Jesús Ramirez has forgotten, as the saying goes, more about Photoshop than most people will ever know. So, encountering some hilarious & annoying Remove Tool fails…
.@Photoshop AI fail: trying to remove my sons heads (to enable further compositing), I get back… whatever the F these are. pic.twitter.com/U8WtoUh2qK
— John Nack (@jnack) December 8, 2025
…reminded me that I should check out his short overview on “How To Remove Anything From Photoshop.”
This season my alma mater has been rolling out sport-specific versions of the classic leprechaun logo, and when the new basketball version dropped today, I decided to have a little fun seeing how well Nano Banana could riff on the theme.
My quick take: It’s pretty great, though applying sequential turns may cause the style to drift farther from the original (more testing needed).
I dig it. Just for fun, I asked Google’s @NanoBanana to create more variations for other sports: pic.twitter.com/i3CBTr8bpp
— John Nack (@jnack) December 9, 2025
I generally love shallow depth of field & creamy bokeh, but this short overview makes a compelling case for why Spielberg has almost always gone in the opposite direction:
Interesting—if not wholly unexpected—finding: People dig what generative systems create, but only if they don’t know how the pixel-sausage was made. ¯\_(ツ)_/¯
AI created visual ads got 20% more clicks than ads created by human experts as part of their jobs… unless people knew the ads are AI-created, which lowers click-throughs to 31% less than human-made ads
Importantly, the AI ads were selected by human experts from many AI options pic.twitter.com/EJkZ1z05FO
— Ethan Mollick (@emollick) December 6, 2025
…you give back flying lighthouses (duh!).
(made with @grok) pic.twitter.com/nGWMLK170Z
— John Nack (@jnack) December 1, 2025
Seriously, its mind (?) is gonna be blown. 🙂
“No one on X is calling anything ‘Nano Banana’ or ‘Gemini 2.5 Flash Image’ in any consistent or meaningful way.”
I’m not so sure I agree 100% with your policework there, @Grok… pic.twitter.com/P5kGOfg5Ln
— John Nack (@jnack) December 4, 2025
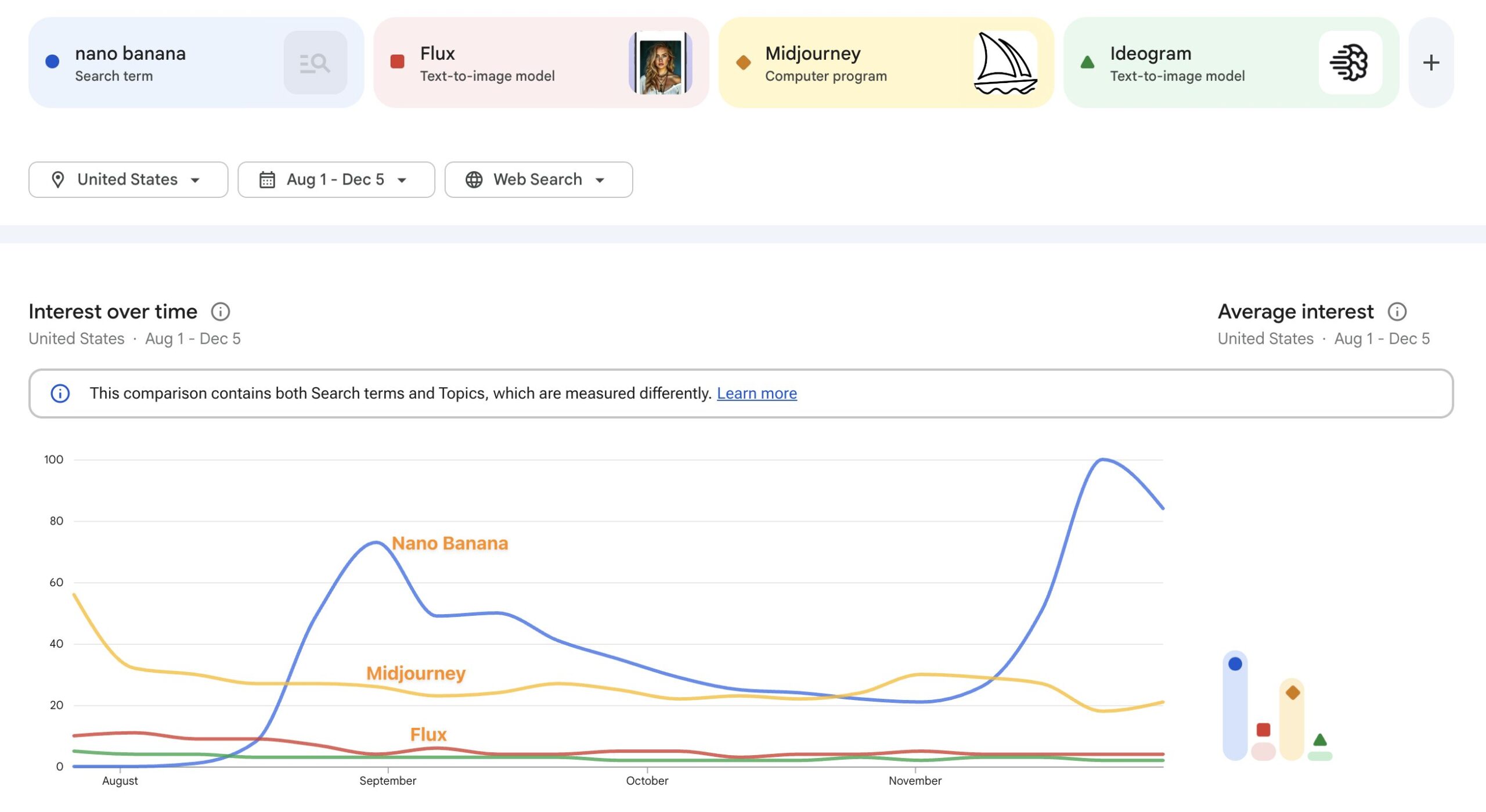
Here’s some actual data for relative interest in Nano Banana, Flux, Midjourney, and Ideogram:
That’s my core takeaway from this great conversation, which will give you hope.
Slack & Flickr founder Stewart Butterfield, whose We Don’t Sell Saddles Here memo I’ve referenced countless times, sat down for a colorful & wide-ranging talk with Lenny Rachitsky. For the key points, check out this summary, or dive right into the whole chat. You won’t regret it.
Visual summary courtesy of NotebookLM:

(00:00) Introduction to Stewart Butterfield
(04:58) Stewart’s current life and reflections
(06:44) Understanding utility curves
(10:13) The concept of divine discontent
(15:11) The importance of taste in product design
(19:03) Tilting your umbrella
(28:32) Balancing friction and comprehension
(45:07) The value of constant dissatisfaction
(47:06) Embracing continuous improvement
(50:03) The complexity of making things work
(54:27) Parkinson’s law and organizational growth
(01:03:17) Hyper-realistic work-like activities
(01:13:23) Advice on when to pivot
(01:18:36) The importance of generosity in leadership
(01:26:34) The owner’s delusion
Being crazy-superstitious when it comes to college football, I must always repay Notre Dame for every score by doing a number of push-ups equivalent to the current point total.
In a normal game, determining the cumulative number of reps is pretty easy (e.g. 7 + 14 + 21), but when the team is able to pour it on, the math—and the burn—get challenging. So, I used Gemini the other day to whip up this little counter app, which it did in one shot! Days of Miracles & Wonder, Vol. ∞.
Introduced my son to vibe coding with @GeminiApp by whipping up a push-up counter for @NDFootball. (RIP my pecs!) #GoIrish
Try it here: https://t.co/fjEnLvTRFK pic.twitter.com/B1YhiNmWSk
— John Nack (@jnack) November 22, 2025
There’s almost no limit to my insane love of practical animal puppetry (usually the sillier, the better—e.g. Triumph, The Falconer), so I naturally loved this peek behind the scenes of Apple’s new spot:
Puppeteers dressed like blueberries. Individually placed whiskers. An entire forest built 3 feet off the ground. And so much more.
Bonus: Check out this look into the making of a similarly great Portland tourism commercial:
I can’t think of a more burn-worthy app than Concur (whose “value prop” to enterprises, I swear, includes the amount they’ll save when employees give up rather than actually get reimbursed).
That’s awesome!
Given my inability to get even a single expense reimbursed at Microsoft, plus similar struggles at Adobe, I hope you won’t mind if I get a little Daenerys-style catharsis on Concur (via @GeminiApp, natch). pic.twitter.com/128VExTDoS
— John Nack (@jnack) November 22, 2025
How well can Gemini make visual sense of various famous plots? Well… kind of well? 🙂 You be the judge.
“The Dude Conceives” — Testing @GeminiApp + @NanoBanana to visually explain The Big Lebowski, Die Hard, Citizen Kane, and The Godfather.
I find the glitches weirdly charming (e.g. Bunny Lebowski as actual bunny!). pic.twitter.com/dT3X3423Ee
— John Nack (@jnack) November 24, 2025
I’m blown away by these one-shot results that I achieved via Gemini while walking my dogs:
OMG: “@GeminiApp, please remove the tarp to reveal the vehicle beneath.” Truly nano-bananas! pic.twitter.com/9edJ0SRvTJ
— John Nack (@jnack) November 25, 2025
The only thing more amazing is just how little wonderment these advances attract. We metabolize—and trivialize—breakthroughs at an astonishing rate.
The ever thoughtful Blaise Agüera y Arcas (CTO of Technology & Society at Google) recently sat down for a conversation with the similarly deep-thinking Dan Faggella. I love that I was able to get Gemini to render a high-level view of the talk:
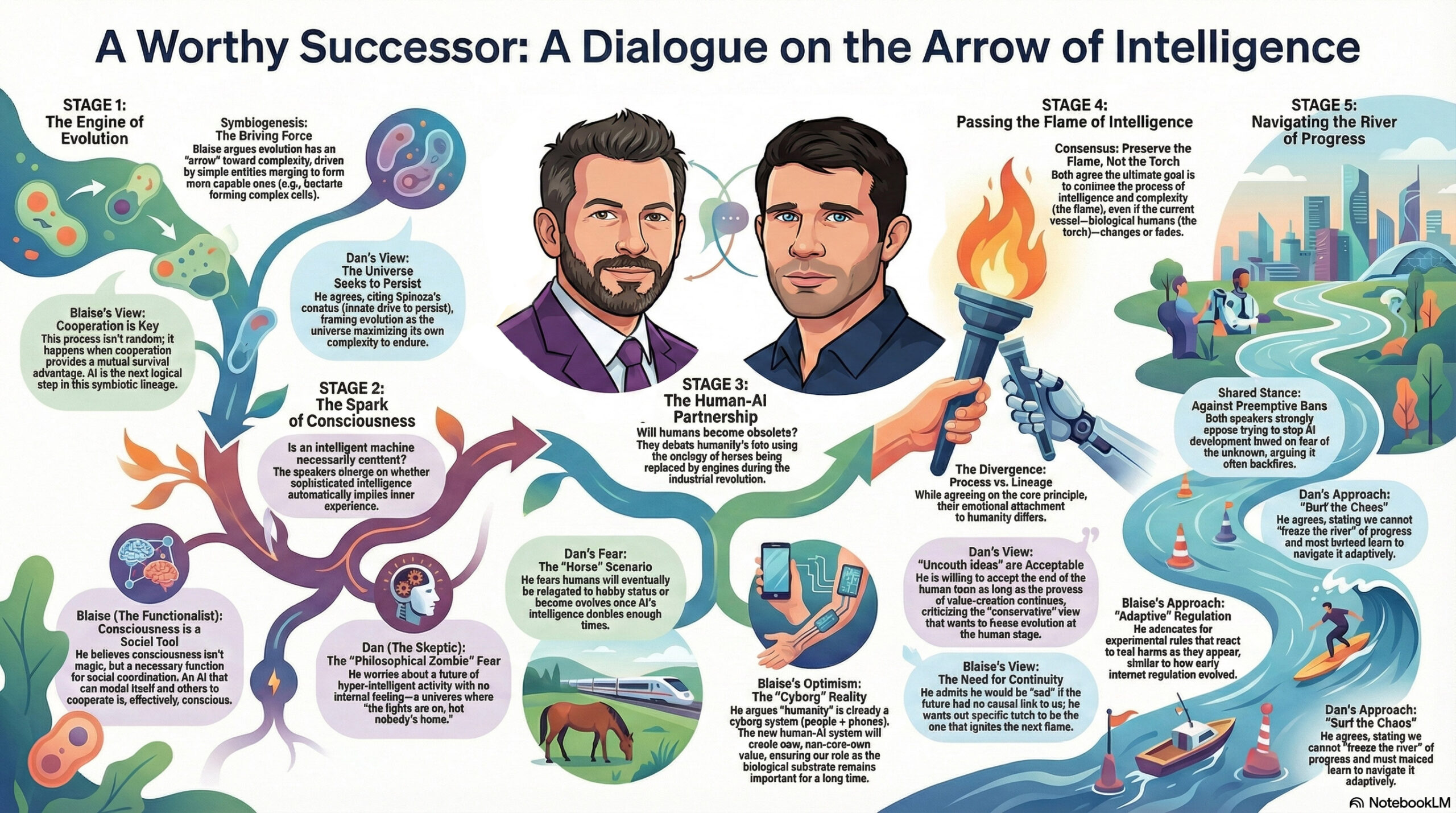
My workflow, FWIW:
Here’s the stimulating chat itself:
Wow—check out the infographic & video it made for me:
NotebookLM one-shotted this video based on the same source. Like, whoever this dude is, I’d hire him! pic.twitter.com/CNdyJUdF8D
— John Nack (@jnack) November 21, 2025
I feel like I’m gonna get at least briefly obsessed with doing this for friends—e.g. my coach Dave:

The very definition of “Tough But Fair.” :-p
IYKYK.
“Project Clippy. Status: Eternal Torment.”
“I see you’re trying to avoid me… You can’t.”AGI arrives, as Nano Banana inside Photoshop dunks on Microsoft Clippy https://t.co/ohxhpB63PF pic.twitter.com/1F5toWYrYr
— John Nack (@jnack) November 21, 2025
Creating clean vectors has proven to be an elusive goal. Firefly in Illustrator still (to my knowledge) just generates bitmaps which then get vectorized. Therefore this tweet caught my attention:
Free-form SVG generation has always been an incredibly hard problem – a challenge I’ve worked on for two years. But with #Gemini3, everything has changed! Now, everyone is designer.
Proud of the amazing team behind breakthrough, and always excited for our future release! https://t.co/rlpUdgjY5Y pic.twitter.com/yeJG36lzKm
— Mu Cai (@MuCai7) November 19, 2025
In my very limited testing so far, however, results have been, well, impressionistic. 🙂


Here’s a direct comparison of my friend Kevin’s image (which I received as an image) vectorized via Image Trace (way more points than I’d like, but generally high fidelity), vs. the same one converted to SVG via Gemini(clean code/lines, but large deviation from the source drawing):

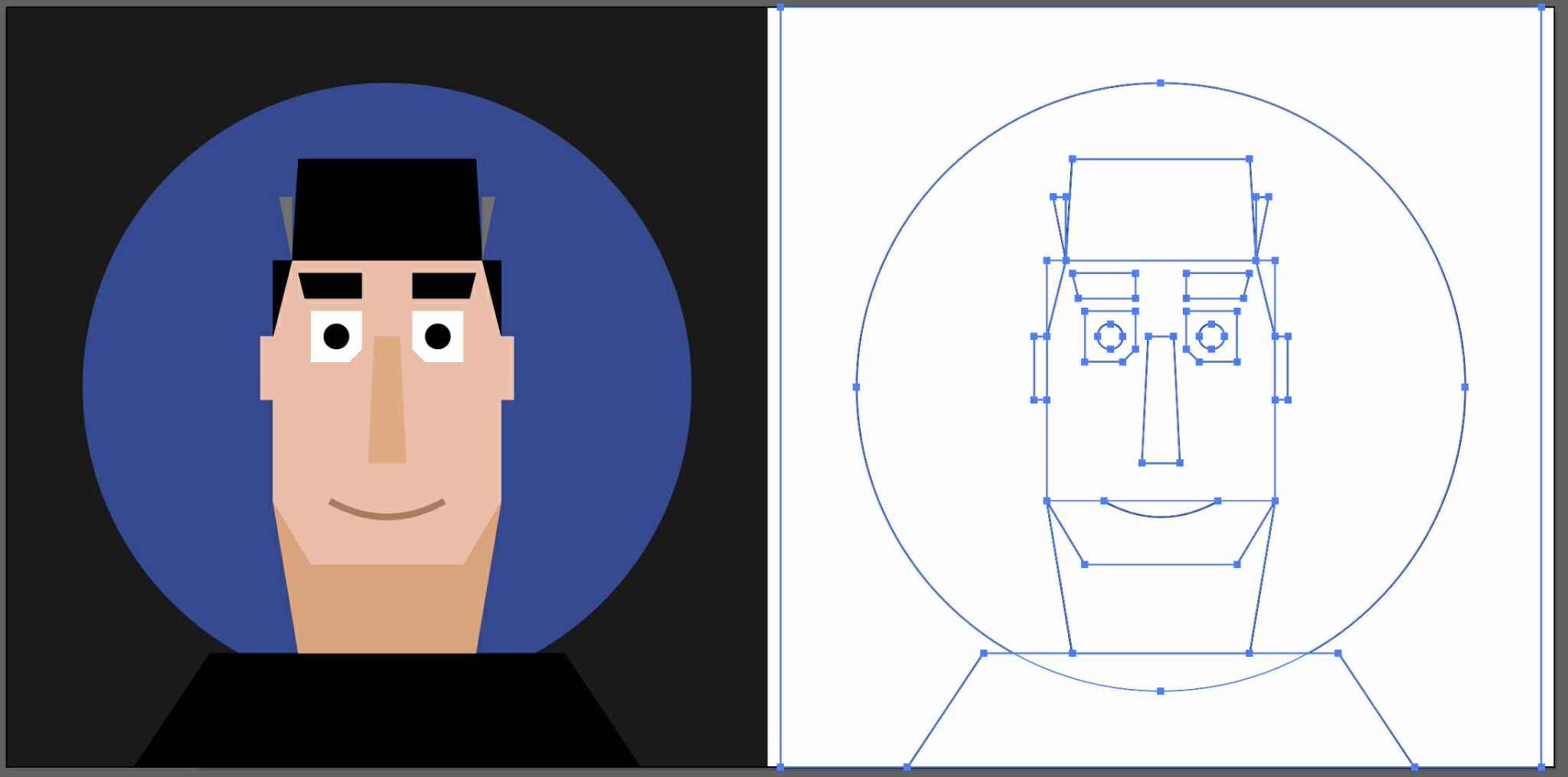
But hey, give it time. For now I love seeing the progress!
Passion is contagious, and I love when people deeply care what they’re bringing into the world. I had no idea I could find the details of fast-food chicken so interesting, but dang if founder Todd Graves’s enthusiasm doesn’t jump right off the screen. Seriously, give it a watch!
Nice clip for any product maker.
(also highlights how every business is complex when you get into the details – it is useful to remember this because many in tech give the excuse “oh, my product is complex and special” – EVERYTHING is complex and it’s your job to deal with that) https://t.co/zgd4uAsGsl
— Shreyas Doshi (@shreyas) November 16, 2025
I’m reminded of Richard Feynman’s keen observation:

More tangentially, this gets me thinking back to my actor friends’ appreciation of Don Cheadle’s craft in this scene from Boogie Nights. “I could watch that guy pick out donuts all day!” And even though I can’t grok the work nearly as deeply as they do, I love how much they love it.
My buddy Bilawal recently sat down with Canva cofounder & Chief Product Officer Cameron Adams for an informative conversation. These points, among others, caught my attention:
00:00 – Canva’s $32B Empire the future of Design
02:26 – Design for Everyone: Canva’s Origin Story
04:19 – Why Canva Bet on the Web
07:29 – How Have Canva Users Changed Over the Years?
12:14 – Why Canva Isn’t Just Unbundling Adobe
14:50 – Canva’s AI Strategy Explained
18:12 – What Does Designing With AI Look Like?
22:55 – Scaling Content with Sheets, Data, and AI
27:17 – What is Canva Code?
29:38 – How Does Canva Fit Into Today’s AI Ecosystem?
32:35 – Why Adobe and Microsoft Should Be Worried
37:52 – Will Canva Expand Into Video Creation?
41:10 – Will AI Eliminate or Expand Creative Jobs?
“What was that?? But why??” :-p
On Friday I got to meet Dr. Fei-Fei Li, “the godmother of AI,” at the launch party for her new company, World Labs (see her launch blog post). We got to chat a bit about a paradox of complexity: that as computer models for perceiving & representing the world grow massively more sophisticated, the interfaces for doing common things—e.g. moving a person in a photo—can get radically simpler & more intentional. I’ll have more to say about this soon.
Meanwhile, here’s her fascinating & wide-ranging conversation with Lenny Rachitsky. I’m always a sucker for a good Platonic allegory-of-the-cave reference. 🙂
From the YouTube summary:
(00:00) Introduction to Dr. Fei-Fei Li
(05:31) The evolution of AI
(09:37) The birth of ImageNet
(17:25) The rise of deep learning
(23:53) The future of AI and AGI
(29:51) Introduction to world models
(40:45) The bitter lesson in AI and robotics
(48:02) Introducing Marble, a revolutionary product
(51:00) Applications and use cases of Marble
(01:01:01) The founder’s journey and insights
(01:10:05) Human-centered AI at Stanford
(01:14:24) The role of AI in various professions
(01:18:16) Conclusion and final thoughts
And here’s Gemini’s solid summary of their discussion of world models:
I’m not fully sure what this rather eye-popping little demo says about how our brains perceive reality, and thus what we can & cannot trust, but dang if it isn’t interesting:
Secret Squirrel rides again!
I was so chuffed to text my wife from the Adobe MAX keynote and report that the next-gen video editor she’d kicked off as PM several years ago has now come to the world, at least in partial form, as the new Firefly Video Editor (currently accepting requests for access). Here our pal Dave Werner provides a characteristically charming tour:
“Jesus Christ!!” — my 16yo Lego lover
View this post on Instagram
My old pal Sam is one of the most thoughtful, down-to-earth guys you’re ever likely to meet in the design community, and if you’re looking for a calm but re-energizing way to spend a couple of minutes, I think you’ll really enjoy his seven-minute talk below. I won’t spoil anything, but do trust me. 🙂
I thought this was a pretty interesting & thoughtful conversation. It’s interesting to think about ways to evaluate & reward process (hard work through challenges) and not just product (final projects, tests, etc.). AI obviously enables a lot of skipping the former in pursuit of the latter—but (shocker!) people then don’t build knowhow around solving problems, or even remember (much less feel pride in) the artifacts they produce.
The issues go a lot deeper, to the very philosophy of education itself. So we sat down and talked to a lot of teachers — you’ll hear many of their voices throughout this episode — and we kept hearing one cri du coeur again and again: What are we even doing here? What’s the point?
Links, courtesy of the Verge team:
Check out MotionStream, “a streaming (real-time, long-duration) video generation system with motion controls, unlocking new possibilities for interactive content generation.” It’s said to run at 29fps on a single H100 GPU (!).
MotionStream: Real-time, interactive video generation with mouse-based motion control; runs at 29 FPS with 0.4s latency on one H100; uses point tracks to control object/camera motion and enables real-time video editing.https://t.co/fFi9iB9ty7 pic.twitter.com/zKb9u3bj9g
— Wildminder (@wildmindai) November 4, 2025
What I’m really wondering, though, it whether/when/how an interactive interface like this can come to Photoshop & other image-editing environments. I’m not yet sure how the dots connect, but could it be paired with something like this model?
Qwen Image Multiple Angles LoRA is an exquisitely trained LoRA!˚₊‧꒰ა
Keep character and scenes consistent, and flies the camera around! Open source got there! One of the best LoRAs I’ve come across lately pic.twitter.com/1mkmCpXgIY
— apolinario (@multimodalart) November 5, 2025
Oh man, this parody of the messaging around AI-justified (?) price increases is 100% pitch perfect. (“It’s the corporate music that sends me into a rage.”)
View this post on Instagram
My friend Bilawal got to sit down with VFX pioneer John Gaeta to discuss “A new language of perception,” Bullet Time, groundbreaking photogrammetry, the coming Big Bang/golden age of storytelling, chasing “a feeling of limitlessness,” and much more.
In this conversation:
Continue reading— How Matrix VFX techniques became the prototypes for AI filmmaking tools, game engines, and AR/VR systems
— How The Matrix team sourced PhD thesis films from university labs to invent new 3D capture techniques
— Why “universal capture” from Matrix 2 & 3 was the precursor to modern volumetric video and 3D avatars
— The Matrix 4 experiments with Unreal Engine that almost launched a transmedia universe based on The Animatrix
— Why dystopian sci-fi becomes infrastructure (and what that means for AI safety)
— Where John is building next: Escape.art and the future of interactive storytelling
I’m pleased to see that as promised back in May, Photoshop has added a “Dynamic Text” toggle that automatically resizes the size of the letters in each line to produce a visually “packed” look:
Results can be really cool, but because the model has no knowledge of the meaning and importance of each word, they can sometimes look pretty dumb. Here’s my canonical example, which visually emphasizes exactly the wrong thing:

I continue to want to see the best of both worlds, with a layout engine taking into account the meaning & thus visual importance of words—like what my team shipped last year:

I’m absolutely confident that this can be done. I mean, just look at the kind of complex layouts I was knocking out in Ideogram a year ago.

The missing ingredient is just the link between image layouts & editability—provided either by bitmap->native conversion (often hard, but doable in some cases), or by in-place editing (e.g. change “Merry Christmas” to “Happy New Year” on a sign, then regenerate the image using the same style & dimensions)—or both.
Bonus points go to the app & model that enable generation with transparency (for easy compositing), or conversion to vectors—or, again, ¿porque no los dos? 🙂
I recently shared a really helpful video from Jesús Ramirez that showed practical uses for each model inside Photoshop (e.g. text editing via Flux). Now here’s a direct comparison from Colin Smith, highlighting these strengths:
These specific examples are great, but I continue to wish for more standardized evals that would help produce objective measures across models. I’m investigating the state of the art there. More to share soon, I hope!
Improvements to imaging continues its breakneck pace, as engines evolve from “simple” text-to-image (which we considered miraculous just three years ago—and which I still kinda do, TBH) to understanding time & space.
Now Emu (see project page, code) can create entire multi-page/image narratives, turn 2D images into 3D worlds, and more. Check it out:
Can’t wait to try this out!
We’ve been thinking a lot about how generative AI can make editing feel faster, smarter, and more intuitive without losing the control creators love.
Today at #AdobeMAX, the #AdobeFirefly team previewed Layered Image Editing: bringing the power of layers and compositing together… pic.twitter.com/VVPtv9hVbK
— Alexandru Costin (@acostin) October 28, 2025
I’m down in LA having tons of great conversations around AI and the future of creativity. If you want to chat, please hit me up. firstname dot lastname at gmail.
“Nodes, nodes, nodes!” — my exasperated then-10yo coming home from learning Unreal at summer camp 🙂
Love ’em or hate ’em, these UI building blocks seem to be everywhere these days—including in Runway’s new Workflows environment:
Introducing Workflows, a new way to build your own tools inside of Runway.
Now you can create your own custom node-based workflows chaining together multiple models, modalities and intermediary steps for even more control of your generations. Build the Workflows that work for… pic.twitter.com/5VHABPj8et
— Runway (@runwayml) October 21, 2025
Hmm—consider me intrigued:
Alloy is AI Prototyping built for Product Management:
➤ Capture your product from the browser in one click
➤ Chat to build your feature ideas in minutes
➤ Share a link with teammates and customers
➤ 30+ integrations for PM teams: Linear, Notion, Jira Product Discovery, and more
Check out the brief demo:
It’s official – I’m excited to introduce Alloy (@alloy_app), the world’s first tool for prototypes that look exactly like your product.
All year, PMs and designers have struggled with off-brand prototypes – built with “app builder” tools that look nothing like their existing… pic.twitter.com/DztKl2HtQg
— Simon Kubica (@simon_kubica) September 23, 2025
Twitter (yes, always “Twitter”) can be useful, but a ton of the AI-related posts there are often fairly superficial and/or impractical rehashes of eye candy that garners attention & not much else.
By contrast, Photoshop expert Jesús Ramirez has put together a really solid, nutrient-dense tour—complete with all his prompts—that I think you’ll find immediately useful. Dive on in, or jump directly to one of the topics linked below.
I particularly like this demo of using Flux to modify the text in an image:

I really enjoyed Jon Stewart’s super accessible, thoughtful conversation with AI pioneer Geoffrey Hinton. Now I’m constantly going to be thinking about edge detectors, neurons, and beaks!
I was initially surprised to see VSCO tapping into Flux for generative smarts, but it makes sense: they’re leaning on it to add really good object removal—and not, at least for the moment, to make larger changes. It’ll be interesting to see how their user community responds, and whether they’ll tip some additional toes into these waters (e.g. for creative relighting).
I had a great time chatting with my fellow former Adobe PM Demian Borba about all things AI (creativity, ethics, ownership, value, and more). You can check out the conversation below, and in case it’s of interest, I used Gemini inside YouTube to create a summary of topics we discussed.
Creative Director Alexia Adana constantly explores new expressive tech & writes thoughtfully about her findings. I was kind of charmed to see her deploying the latest tools to form sort of a self-promotional AI herald (below), riding ahead with her tidings:
“Call your abuela! She is missing you and she has nothing to do.” :-p
Remember those studies showing that using AI makes us dumber? Yeah, about that… 🙂
This long strip is equal parts heartfelt & hilarious. You should read the whole thing (really, it’s very good), but this bit stuck with me:

As did this sick burn :-p

The team at BFL is celebrating some of the most interesting, creative uses of the Flux model. Having helped bring the Vanishing Point tool to Photoshop, and always having been interested in building more such tech, this one caught my eye:
Best Overall Winner
Perspective Control using Vanishing Points (jschoormans)
Just like Renaissance artists who start with perspective grids, this Kontext LoRa lets you control the exact perspective point in AI-generated images. pic.twitter.com/phAY41KYdP— Black Forest Labs (@bfl_ml) October 1, 2025
“With just a few clicks and the energy demands of a small European nation, you can create an ass-load of dumb shit with zero meaning!” :-p
Back when I worked in Google Research, my teammates developed fast models divide images & video into segments (people, animals, sky, etc.). I’m delighted that they’ve now brought this tech to Snapseed:
The new Object Brush in Snapseed on iOS, accessible in the “Adjust” tool, now lets you edit objects intuitively. It allows you to simply draw a stroke on the object you want to edit and then adjust how you want it to look, separate from the rest of the image.
Check out the team blog post for lots of technical details on how the model was trained.
The underlying model powers a wide range of image editing and manipulation tasks and serves as a foundational technology for intuitive selective editing. It has also been shipped in the new Chromebook Plus 14 to power AI image editing in the Gallery app. Next, we plan to integrate it across more image and creative editing products at Google.
I was pleasantly surprised to see my old Google Photos manager David Lieb pop up in this brief clip from Y Combinator, where he now works, discussing how the current batch of AI-enabled apps somewhat resembles the original “horseless carriages.” It’s fun to contemplate what’ll come next.
View this post on Instagram
“A few weeks ago,” writes John Gruber, “designer James Barnard made this TikTok video about what seemed to be a few mistakes in HBO’s logo. He got a bunch of crap from commenters arguing that they weren’t mistakes at all. Then he heard from the designer of the original version of the logo, from the 1970s.”
Check out these surprisingly interesting three minutes of logo design history:
@barnardco “Who. Cares? Unfollowed” This is how a *lot* of people responded to my post about the mistake in the HBO logo. For those that didn’t see it, the H and the B of the logo don’t line up at the top of the official vector version from the website. Not only that, but the original designer @Gerard Huerta700 got in touch! Long story short, we’re all good, and Designerrrs™ community members can watch my interview with Gerard Huerta where we talk about this and his illustrious career! #hbo #typography #logodesign #logo #designtok original sound – James Barnard
As much as one can be said to enjoy thinking through the details of how to evaluate AI (and it actually can be kinda fun!), I enjoyed this in-depth guide from Hamel Husain & Shreya Shankar.
All year I’ve been focusing pretty intently on how to tease out the details of what makes image creation & editing models “good” (e.g. spelling, human realism, prompt alignment, detail preservation, and more). This talk pops up a level, focusing more on holistic analysis of end-to-end experiences. If you’re doing that kind of work, or even if you just want to better understand the kind of thing that’s super interesting to hiring managers now, I think you’ll find watching this to be time well spent.