“People will forget you said, people will forget what you did, but people will never forget how you made them feel.” — Maya Angelou
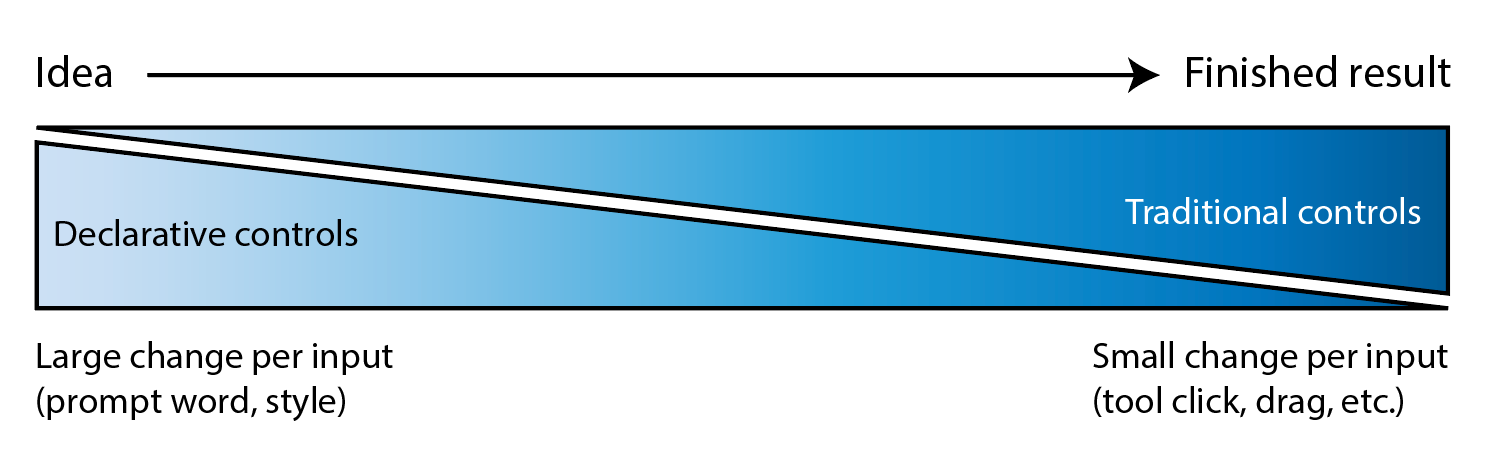
I’ve reflected on this maxim countless times over the last couple of years, as I’ve considered the relationships I want with AI—particularly with notional creative partners. I want a partner who cares—who (which?) actually takes the time to get to know me, asking thoughtful questions, noodling on answers, and genuinely taking my feedback to heart.
I thought of this while listening to Stewart Brand talking to Ezra Klein the other day. Check out this poetic & provocative passage:
Well, it wound up that, basically, most of the book is Chapter 2, “Vehicles.” And the land vehicle that humans have used for 6,000 years is a horse, and the horse takes a lot of maintenance.
I’ll read something here from the book, if I may. There’s this philosopher named Albert Borgmann who wrote:
You cannot remain unmoved by the gentleness and conformation of a well-bred and well-trained horse — more than a thousand pounds of big-boned, well-muscled animal, slick of coat and sweet of smell, obedient and mannerly, and yet forever a menace with its innocent power and ineradicable inclination to seek refuge in flight, and always a burden with its need to be fed, wormed and shod, with its liability to cuts and infections, to laming and heaves. But when it greets you with a nicker, nuzzles your chest and regards you with a large and liquid eye, the question of where you want to be and what you want to do has been answered.
And I end with: “I wonder if that might come again someday — a vehicle that cares back.”