Before commencing his long & distinguished career as an architect, 19yo Victor Lundy captured life at an American GI.
He drew out his experiences from training at Fort Jackson (May 1944) to his journey across the Atlantic and then his time in France. In total, he produced a visual diary with 158 pencil sketches brings to life the wartime experience. Lundy applied his drawing skills to what was around him—training at Fort Jackson, South Carolina; forced marches; men at rest; the PX and tents; New York Harbor; aboard ship in the Atlantic crossing; Cherbourg Harbor; and French villages. Many vivid portraits of fellow soldiers and frontline danger also fill the pages. The sketches cover May to November 1944 when Lundy was wounded, with some gaps where notebooks were lost.
The eight surviving sketchbooks are spiral bound and 3 x 5 inches—small enough to fit in a breast pocket. Lundy used black Hardtmuth leads (a drawing pencil) and sketched quickly. “For me, drawing is sort of synonymous with thinking.”
Side note: “Macrófago” is 100% the best word I’ve learned all week.
Sincitium is finally here.
We are pleased to present our latest piece: a concept trailer created specifically for the @runwayml Big Pitch Contest. For this project, we wanted to explore a completely different aesthetic from our usual studio style, and this film is the result of… pic.twitter.com/FHKkZWjjJg
Man, it must be nearly 20 years ago that we started envisioning drag-and-drop-simple composition and compositing in Photoshop—back when gradient-domain painting & blending was the emerging hotness. After plenty of false starts, could these simple interaction patterns finally become mainstream? Maybe! I must know more of this witchcraft:
Do you like image editing? Don’t like prompt engineering? Want to see what a giraffe-duck hybrid looks like? If you answered yes at least once, you may like our new #SIGGRAPH2026 paper: LooseRoPE, which presents a new, prompt-free way to edit images using simple visual cues pic.twitter.com/JMzMDHJ9wE
Despite—or perhaps because of—growing up without MTV (I know, the Gen X horror...), I’ve always had a real fascination with the video for Peter Gabriel’s Sledgehammer. Check out its rad zoetrope picture disc incarnation:
The zoetrope picture disc 12” of Sledgehammer is out this Saturday as part of #RecordStoreDay
Designed by Drew Tetz and Marc Bessant.
Please visit the Record Store Day website to check out the full list of releases and also visit your local record store to see what they plan to… pic.twitter.com/arJfTYLk4k
Long dog walks are for nothing if not visualizing whatever silliness pops into my head—which today happened to be our puppy Ziggy becoming an impossible object called a “Ziggule.”
I shared this with my cousin Alicia, who does a tremendous amount of work sheltering & rescuing dogs in Austin, and she requested a portrait of their current foster pooch (Tesseract). I was of course all too happy to oblige:
As it happens, folks at Google have had the same idea, and they’ve been putting Nano Banana to work helping zhuzh up pics of shelter pets in hopes of helping them find their forever homes. Let’s hear it for using AI & old-fashioned human creativity for good!
Photos play a big role in pet adoption.
We’ve teamed up with shelters across the country to give rescue pets glamorous headshots that show off their personalities, made with Nano Banana Pro.
The older I get, the harder it is to get the Kids These Days™ to grok just what a road-to-Damascus moment the arrival of the Mac presented. I flap my arms like some conspiracy nut at his cork board, trying in vain to convey the idea that in the pre-Mac days, personal computer “art” consisted of pecking out some green ASCII blocks on an Apple ][. Okay, grandpa, let’s get you to bed…
Anyway, predating even me (heh) is this glimpse of how computer animation was painstakingly eeked out via data tape (!) back in 1971.
I try not to curse on this blog, doing so maybe a dozen times in 20+ (!!) years of posting. But circa 2013-2017, when I saw what felt like uncritical praise for Adobe’s voice-driven editing prototypes, I called bullshit.
The high-level concept was fine, but the tech at the time struck me as the worst of both worlds: the imprecision of language (e.g. how does a normal person know the term “saturation,” and how does an expert describe exactly how much they want?) combined with the fragility of traditional selection & adjustment algorithms.
Now, however, generative tech can indeed interpret our language & effect changes—and in the case of Krea’s new realtime mode, in a highly responsive way:
Whether or not voice per se becomes a popular modality here, closing the gap between idea & visual is just so seductive. To emphasize a previously made point:
We simply have not started rethinking interactions from the grounds up.
So many possibilities wide open when you think of human – AI in micro feedback loops vs automation alone or classic back and forth. https://t.co/iVKb02SbdU
When it rains, it pours: No sooner did I post about text->vector than I saw two new entrants in that space. The new Quiver AI is claimed to have “solved vector design with AI”:
Introducing @QuiverAI, a new AI lab and product company focused on frontier vector design.
We’ve raised an $8.3M seed round led by @a16z, with support from amazing angels and investors.
Our first model, Arrow-1.0, generates SVGs from images and text. It’s available now in… pic.twitter.com/mLoeM2UpGf
Here’s my first quick test, in which Quiver & Illustrator utterly smoke direct chat->vector output in Gemini & ChatGPT:
Testing text->vector in the new @QuiverAI vs. Adobe Illustrator and (yikes!) Gemini and ChatGPT. (Prompt: “A three-quarter view of a silver 1990 Mazda Miata.”) pic.twitter.com/MjTuFYLGQ3
Elsewhere, Hero Studio promises great image->SVG conversion. I’ve applied for access & am eager to take it for a spin:
You can now bring your images to life, just upload any image and it turns it into a clean and precise SVG. we’re using a custom model specifically trained for SVG recognition and generation. the results are insane pic.twitter.com/s6e4tJ4IWm
When we launched Firefly three years ago (!), we talked up prompt-based vector creation. When the feature later arrived in Illustrator, it was really text-to-image-to-tracing. That could be fine, actually, provided that the conversion process did some smart things around segmenting the image, moving objects onto their own layers, filling holes, and then harmoniously vectorizing the results. I’m not sure whether Adobe actually got around to shipping that support.
In any case, Recraft now promises create vector creation directly from prompts:
AniStudio exists because we believe animation deserves a future that’s faster, more accessible, and truly built for the AI era—not as an add-on, but from the ground up. This isn’t a finished story. It’s the first step of a new one, and we want to build it together with the people who care about animation the most.
The moment I switched on gravity was the moment everything changed.
Lines I had just drawn started to fall, swing, and collide like they were suddenly alive inside my room. A simple sketch became an object with weight. A doodle turned into something that could react back. It is one of those Vision Pro moments where you catch yourself smiling because it feels playful in a way you do not see coming.
Of course, Old Man Nack™ feels like being a little cautious here: Ten years ago (!) my kids were playing in Adobe’s long-deceased Project Dali…
…and five years ago Google bailed on the excellent Tilt Brush 3D painting app it acquired. ¯\_(ツ)_/¯
And yet, and yet, and yet… I Want To Believe. As I wrote back in 2015,
I always dreamed of giving Photoshop this kind of expressive painting power; hence my long & ultimately fruitless endeavor to incorporate Flash or HTML/WebGL as a layer type. Ah well. It all reminds me of this great old-ish commercial:
So, in the world of AI, and with spatial computing staying a dead parrot (just resting & pining for the fjords!), who knows what dreams may yet come?
“Please create a funny infographic showing a cutaway diagram for the world’s most dangerous hospital cuisine: chicken pot pie. It should show an illustration of me (attached) gazing in fear…” pic.twitter.com/txnuamvGVq
This season my alma mater has been rolling out sport-specific versions of the classic leprechaun logo, and when the new basketball version dropped today, I decided to have a little fun seeing how well Nano Banana could riff on the theme.
My quick take: It’s pretty great, though applying sequential turns may cause the style to drift farther from the original (more testing needed).
I can’t think of a more burn-worthy app than Concur (whose “value prop” to enterprises, I swear, includes the amount they’ll save when employees give up rather than actually get reimbursed).
That’s awesome!
Given my inability to get even a single expense reimbursed at Microsoft, plus similar struggles at Adobe, I hope you won’t mind if I get a little Daenerys-style catharsis on Concur (via @GeminiApp, natch). pic.twitter.com/128VExTDoS
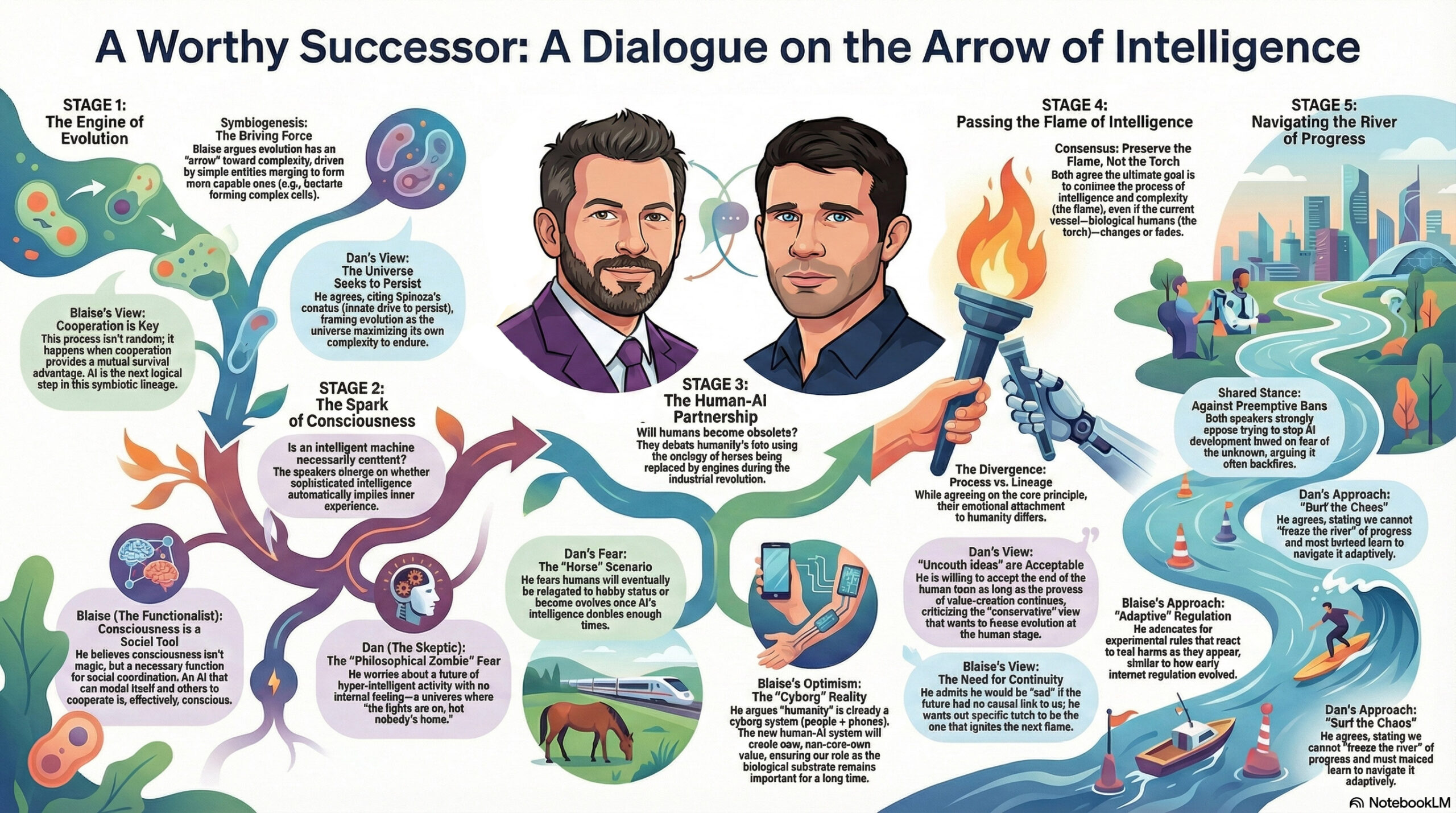
The ever thoughtful Blaise Agüera y Arcas (CTO of Technology & Society at Google) recently sat down for a conversation with the similarly deep-thinking Dan Faggella. I love that I was able to get Gemini to render a high-level view of the talk:
Creating clean vectors has proven to be an elusive goal. Firefly in Illustrator still (to my knowledge) just generates bitmaps which then get vectorized. Therefore this tweet caught my attention:
Free-form SVG generation has always been an incredibly hard problem – a challenge I’ve worked on for two years. But with #Gemini3, everything has changed! Now, everyone is designer.
In my very limited testing so far, however, results have been, well, impressionistic. 🙂
Here’s a direct comparison of my friend Kevin’s image (which I received as an image) vectorized via Image Trace (way more points than I’d like, but generally high fidelity), vs. the same one converted to SVG via Gemini(clean code/lines, but large deviation from the source drawing):
But hey, give it time. For now I love seeing the progress!
The team at BFL is celebrating some of the most interesting, creative uses of the Flux model. Having helped bring the Vanishing Point tool to Photoshop, and always having been interested in building more such tech, this one caught my eye:
Best Overall Winner
Perspective Control using Vanishing Points (jschoormans) Just like Renaissance artists who start with perspective grids, this Kontext LoRa lets you control the exact perspective point in AI-generated images. pic.twitter.com/phAY41KYdP
Turntable is now available in the Adobe #Illustrator Public Beta Build 29.9.14!!!
A feature that lets you “turn” your 2D artwork to view it from different angles. With just a few steps, you can generate multiple views without redrawing from scratch.
Jesús Ramirez is a master Photoshop compositor, so it’s especially helpful to see his exploration of some of the new tool’s strengths & weaknesses (e.g. limited resolution)—including ways to work around them.
My family, having seen so many of my AI-powered image generations over the last 3 years, is just utterly inured to them. So, for my MiniMe’s 16th, I sketched up the patriotic little HO-scale engine we’re getting him, along with a cute large ground squirrel (to quote the Dude, “Nice marmot”).
I feel like this is my micro version of when the world revolted against too-perfect Instagram culture, swinging towards Snapchat & stories, where “rough is real,” and flaws are a feature. In any case, my dude was happy as a clam—and that’s all that matters to me.
For my son’s birthday, I ditched AI and broke out my pen. Felt good to work without a net. pic.twitter.com/TJedYCPWMj
A while back, Sam Harris & Ricky Gervais discussed the impossibility of translating a joke discovered during a dream (“What noise does a monster make?”) back into our consensus waking reality. Like… what?
I get the same vibes watching ChatGPT try to dredge up some model of me and of… humor?… in creating a comic strip based on our interactions. I find it uncanny, inscrutable, and yet consequently charming all at once.
“Hey ChatGPT, based on what you know about me, please create a four-panel comic you think I’d like…” https://t.co/U7WRfShGRh
Having created 200+ images in just the last month via this still-new image model (see new blog category that gathers some of them), I’m delighted to say that my team is working to bring it to Microsoft Designer, Copilot, and beyond. From the boss himself:
5/ Create: This one is fun. Turn a PowerPoint into an explainer video, or generate an image from a prompt in Copilot with just a few clicks.
We’ve also added new features to make Copilot even more personalized to you, plus a redesigned app built for human-agent collaboration. pic.twitter.com/m1oTf53aai
Back at Adobe we introduced Firefly text-to-vector creation, but behind the scenes it was really text-to-image-to-tracing. That could be fine, actually, provided that the conversion process did some smart things around segmenting the image, moving objects onto their own layers, filling holes, and then harmoniously vectorizing the results. I’m not sure whether Adobe actually got around to shipping that support.
In any event, StarVector promises actual, direct creation of SVG. The results look simple enough that it hasn’t yet piqued my interest enough to spend my time with it, but I’m glad that folks are trying.
I really hope that the makers of traditional vector-editing apps are paying attention to rich, modern, GPU-friendly techniques like this one. (If not—and I somewhat cynically expect that it’s not—it won’t be for my lack of trying to put it onto their radar. ¯\_(ツ)_/¯)
Introducing Vector Feathering — a new way to create vector glow and shadow effects. Vector Feathering is a technique we invented at Rive that can soften the edge of vector paths without the typical performance impact of traditional blur effects. (Audio on) pic.twitter.com/39kfjmFsTJ
I know only what you see below, but Magic Animator (how was that domain name available?) promises to “Animate your designs in seconds with AI,” which sounds right up my alley, and I’ve signed up for their waitlist.
I love seeing the Magnific team’s continued rapid march in delivering identity-preserving reskinning
IT’S FINALLY HERE!
Mystic Structure Reference!
Generate any image controlling structural integrity Infinite use cases! Films, 3D, video games, art, interiors, architecture… From cartoon to real, the opposite, or ANYTHING in between!
This example makes me wish my boys were, just for a moment, 10 years younger and still up for this kind of father/son play. 🙂
Storyboarding? No clue! But with some toy blocks, my daughter’s wild imagination, and a little help from Magnific Structure Reference, we built a castle attacked by dragons. Her idea coming to life powered up with AI magic. Just a normal Saturday Morning. Behold, my daughter’s… pic.twitter.com/52tDZokmIT
“Rather than removing them from the process, it actually allowed [the artists] to do a lot more—so a small team can dream a lot bigger.”
Paul Trillo’s been killing it for years (see innumerable previous posts), and now he’s given a peek into how his team has been pushing 2D & 3D forward with the help of custom-trained generative AI:”
Traditional 2d animation meets the bleeding edge of experimental techniques. This is a behind the scenes look at how we at Asteria brought the old and the new together in this throwback animation “A Love Letter to Los Angeles” and collaboration with music artist Cuco and visual… pic.twitter.com/3eWSdgckXn
A passing YouTube vid made me wonder about the relative strengths of World War II-era bombers, and ChatGPT quickly obliged by making me a great little summary, including a useful table. I figured, however, that it would totally fail at making me a useful infographic from the data—and that it did!
Just for the lulz, I then ran the prompt (“An infographic comparing the Avro Lancaster, Boeing B-17, and Consolidated B-24 Liberator bombers”) through a variety of apps (Ideogram, Flux, Midjourney, and even ol’ Firefly), creating a rogue’s gallery of gibberish & Franken-planes. Check ’em out.
Currently amusing myself with how charmingly bad every AI image generator is at making infographics—each uniquely bizarre! pic.twitter.com/U3cs8ySoVa
I really love the way the visual medium (simply black & white dots) enriches & evolves right alongside its subject matter in this ad for ChatGPT, and I hope we get to hear more soon from the creative team behind it.
If you’re like me, you may well have spent hours of your youth lovingly recreating the iconic designs of pioneering Santa Cruz artist Jim Phillips. My first deck was a Roskopp 6, and I covered countless notebook covers, a leg cast, my bedroom door, and other surfaces with my humble recreations of his work.
That work is showcased in the documentary “Art And Life,” screening on Thursday in Santa Cruz. I hope to be there, and maybe to see you there as well. (To this day I can’t quite get over the fact that “Santa Cruz” is a real place, and that I can actually visit it. Growing up it was like “Timbuktu” or “Shangri-La.” Funny ol’ world.)
It’s a real joy to see my 15yo son Henry’s interest in design & photography blossom, and last night he fell asleep perusing the giant book of vintage logos we scored at the Chicago Art Institute. I’m looking forward to acquainting him with the groundbreaking work of Saul Bass & figured we’d start here:
We present FlipSketch, a system that brings back the magic of flip-book animation — just draw your idea and describe how you want it to move! …
Unlike constrained vector animations, our raster frames support dynamic sketch transformations, capturing the expressive freedom of traditional animation. The result is an intuitive system that makes sketch animation as simple as doodling and describing, while maintaining the artistic essence of hand-drawn animation.
Oh, I love this one!
FlipSketch can generate sketch animations from static drawings using text prompts!
Hmm—”fix” is a strong word for reinterpreting the creative choices & outcomes of an earlier generation of artists, but it’s certainly interesting to see the divisive Christmas movie re-rendered via emerging AI tech (Midjourney Retexturing + Hailuo Minimax). Do you think the results escape the original’s deep uncanny valley? See more discussion here.