I can’t think of a more burn-worthy app than Concur (whose “value prop” to enterprises, I swear, includes the amount they’ll save when employees give up rather than actually get reimbursed).
That’s awesome!
Given my inability to get even a single expense reimbursed at Microsoft, plus similar struggles at Adobe, I hope you won’t mind if I get a little Daenerys-style catharsis on Concur (via @GeminiApp, natch). pic.twitter.com/128VExTDoS
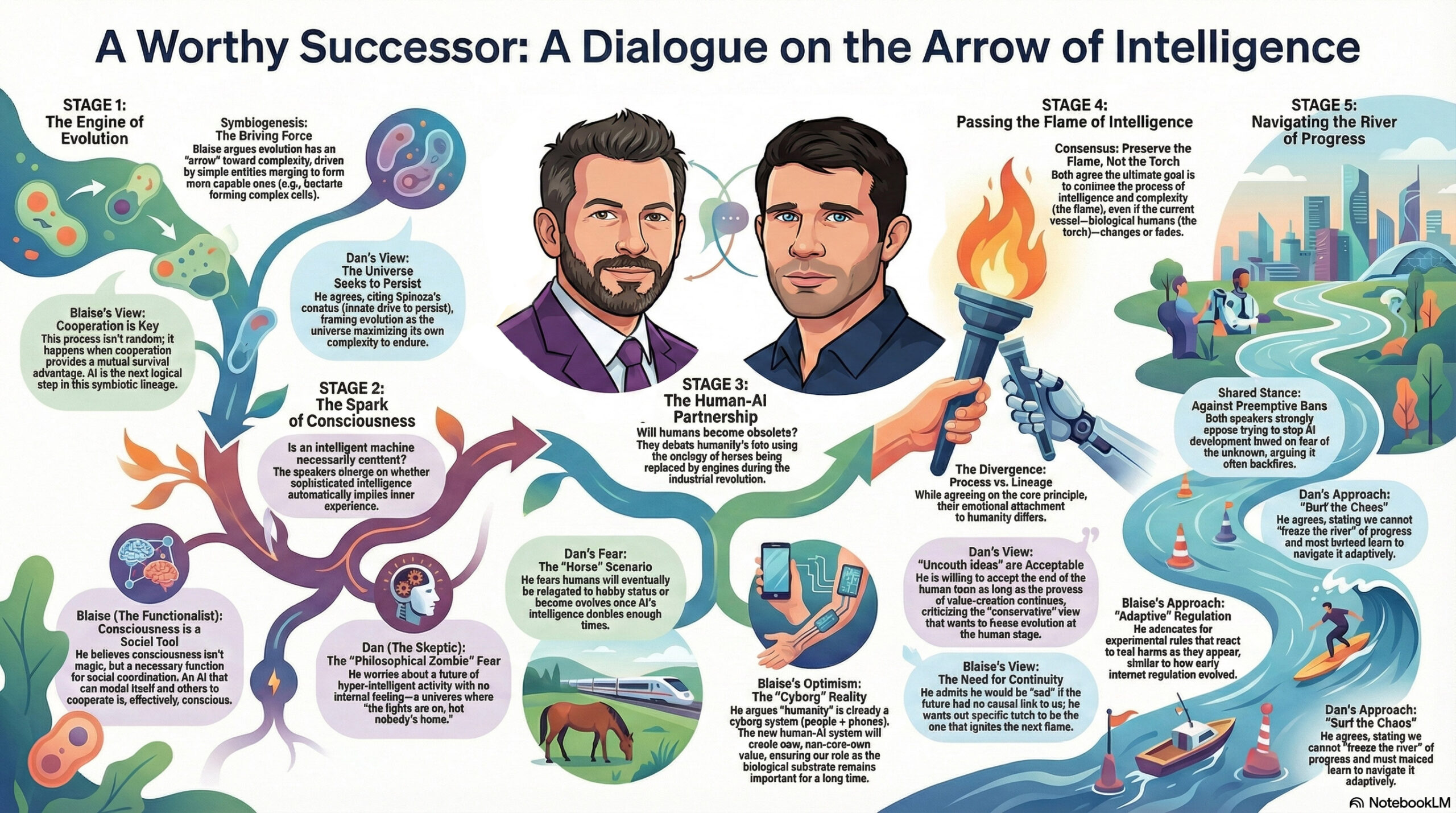
The ever thoughtful Blaise Agüera y Arcas (CTO of Technology & Society at Google) recently sat down for a conversation with the similarly deep-thinking Dan Faggella. I love that I was able to get Gemini to render a high-level view of the talk:
Creating clean vectors has proven to be an elusive goal. Firefly in Illustrator still (to my knowledge) just generates bitmaps which then get vectorized. Therefore this tweet caught my attention:
Free-form SVG generation has always been an incredibly hard problem – a challenge I’ve worked on for two years. But with #Gemini3, everything has changed! Now, everyone is designer.
In my very limited testing so far, however, results have been, well, impressionistic. 🙂
Here’s a direct comparison of my friend Kevin’s image (which I received as an image) vectorized via Image Trace (way more points than I’d like, but generally high fidelity), vs. the same one converted to SVG via Gemini(clean code/lines, but large deviation from the source drawing):
But hey, give it time. For now I love seeing the progress!
Passion is contagious, and I love when people deeply care what they’re bringing into the world. I had no idea I could find the details of fast-food chicken so interesting, but dang if founder Todd Graves’s enthusiasm doesn’t jump right off the screen. Seriously, give it a watch!
Nice clip for any product maker.
(also highlights how every business is complex when you get into the details – it is useful to remember this because many in tech give the excuse “oh, my product is complex and special” – EVERYTHING is complex and it’s your job to deal with that) https://t.co/zgd4uAsGsl
I’m reminded of Richard Feynman’s keen observation:
More tangentially, this gets me thinking back to my actor friends’ appreciation of Don Cheadle’s craft in this scene from Boogie Nights. “I could watch that guy pick out donuts all day!” And even though I can’t grok the work nearly as deeply as they do, I love how much they love it.
My buddy Bilawal recently sat down with Canva cofounder & Chief Product Officer Cameron Adams for an informative conversation. These points, among others, caught my attention:
“Canva is a goal-achievement machine.” That is, users approach it with particular outcomes in mind (e.g. land your first customer, get your first investment), and the feature development team works back from those goals. As the old saying goes, “People don’t want a quarter-inch drill, they want a quarter-inch hole”—i.e. a specific outcome.
They seek to reduce the gap between idea & outcome. This reminded me of the first Adobe promo I saw more than 30 years ago: “Imagine what you can create. Create what you can imagine.”
Measuring the achievement of goals is critical. That includes gathering insights from audience response.
They’re pursuing a three-tiered AI strategy: homegrown foundational models that they need to own (based on deep insight into user behavior); partnerships with state-of-the-art models (e.g. GPT, Veo); and a rich ecosystem and app marketplace (hosting image & music generation and more).
“When you think about AI as a collaborator, it opens up a whole palette of different interactions & product experiences you can deliver.” No single modality (e.g. prompting alone) is ideal for everything from ideation to creation to refinement.
What’s it like to author at a higher level of abstraction? “It’s a dance,” and it’s still a work in progress.
What’s the role of personalization? Responsive content. Personalizing messaging has been a huge driver of Canva’s growth, and they want to bring similar tools & best practices to everyone.
“The real crux of Canva is storytelling.” Video is now used by tens of millions of people. Across media (video, images, presentations), the same challenges appear: Properly complete your idea. Make fine-grained edits. Bring in others & get their feedback.
“Knowing the start & the end, but less of the middle.” AI-enabled tools can remove production drudgery, but one’s starting point & desired outcome remain essential. Start: Fundamental understanding of what works. Ideas, thinking creatively. Elements of editorship & taste are essential. Later: It’s how you express this, measure impact, take insights into the creation loop.
00:00 – Canva’s $32B Empire the future of Design 02:26 – Design for Everyone: Canva’s Origin Story 04:19 – Why Canva Bet on the Web 07:29 – How Have Canva Users Changed Over the Years? 12:14 – Why Canva Isn’t Just Unbundling Adobe 14:50 – Canva’s AI Strategy Explained 18:12 – What Does Designing With AI Look Like? 22:55 – Scaling Content with Sheets, Data, and AI 27:17 – What is Canva Code? 29:38 – How Does Canva Fit Into Today’s AI Ecosystem? 32:35 – Why Adobe and Microsoft Should Be Worried 37:52 – Will Canva Expand Into Video Creation? 41:10 – Will AI Eliminate or Expand Creative Jobs?
On Friday I got to meet Dr. Fei-Fei Li, “the godmother of AI,” at the launch party for her new company, World Labs (see her launch blog post). We got to chat a bit about a paradox of complexity: that as computer models for perceiving & representing the world grow massively more sophisticated, the interfaces for doing common things—e.g. moving a person in a photo—can get radically simpler & more intentional. I’ll have more to say about this soon.
Meanwhile, here’s her fascinating & wide-ranging conversation with Lenny Rachitsky. I’m always a sucker for a good Platonic allegory-of-the-cave reference. 🙂
From the YouTube summary:
(00:00) Introduction to Dr. Fei-Fei Li (05:31) The evolution of AI (09:37) The birth of ImageNet (17:25) The rise of deep learning (23:53) The future of AI and AGI (29:51) Introduction to world models (40:45) The bitter lesson in AI and robotics (48:02) Introducing Marble, a revolutionary product (51:00) Applications and use cases of Marble (01:01:01) The founder’s journey and insights (01:10:05) Human-centered AI at Stanford (01:14:24) The role of AI in various professions (01:18:16) Conclusion and final thoughts
And here’s Gemini’s solid summary of their discussion of world models:
The Motivation: While LLMs are inspiring, they lack the spatial intelligence and world understanding that humans use daily. This ability to reason about the physical world—understanding objects, movement, and situational awareness—is essential for tasks like first response or even just tidying a kitchen 32:23.
The Concept: A world model is described as the lynchpin connecting visual intelligence, robotics, and other forms of intelligence beyond language 33:32. It is a foundational model that allows an agent (human or robot) to:
Create worlds in their mind’s eye through prompting 35:01.
Interact with that world by browsing, walking, picking up objects, or changing things 35:12.
Reason within the world, such as a robot planning its path 35:31.
The Application: World models are considered the key missing piece for building effective embodied AI, especially robots 36:08. Beyond robotics, the technology is expected to unlock major advances in scientific discovery (like deducing 3D structures from 2D data) 37:48, games, and design 37:31.
The Product: Dr. Li co-founded World Labs to pursue this mission 34:25. Their first product, Marble, is a generative model that outputs genuinely 3D worlds which users can navigate and explore 49:11. Current use cases include virtual production/VFX, game development, and creating synthetic data for robotic simulation 53:05.
I’m not fully sure what this rather eye-popping little demo says about how our brains perceive reality, and thus what we can & cannot trust, but dang if it isn’t interesting:
I was so chuffed to text my wife from the Adobe MAX keynote and report that the next-gen video editor she’d kicked off as PM several years ago has now come to the world, at least in partial form, as the new Firefly Video Editor (currently accepting requests for access). Here our pal Dave Werner provides a characteristically charming tour:
My old pal Sam is one of the most thoughtful, down-to-earth guys you’re ever likely to meet in the design community, and if you’re looking for a calm but re-energizing way to spend a couple of minutes, I think you’ll really enjoy his seven-minute talk below. I won’t spoil anything, but do trust me. 🙂
I thought this was a pretty interesting & thoughtful conversation. It’s interesting to think about ways to evaluate & reward process (hard work through challenges) and not just product (final projects, tests, etc.). AI obviously enables a lot of skipping the former in pursuit of the latter—but (shocker!) people then don’t build knowhow around solving problems, or even remember (much less feel pride in) the artifacts they produce.
The issues go a lot deeper, to the very philosophy of education itself. So we sat down and talked to a lot of teachers — you’ll hear many of their voices throughout this episode — and we kept hearing one cri du coeur again and again: What are we even doing here? What’s the point?
Links, courtesy of the Verge team:
A majority of high school students use gen AI for schoolwork | College Board
About a quarter of teens have used ChatGPT for schoolwork | Pew Research
Check out MotionStream, “a streaming (real-time, long-duration) video generation system with motion controls, unlocking new possibilities for interactive content generation.” It’s said to run at 29fps on a single H100 GPU (!).
MotionStream: Real-time, interactive video generation with mouse-based motion control; runs at 29 FPS with 0.4s latency on one H100; uses point tracks to control object/camera motion and enables real-time video editing.https://t.co/fFi9iB9ty7pic.twitter.com/zKb9u3bj9g
What I’m really wondering, though, it whether/when/how an interactive interface like this can come to Photoshop & other image-editing environments. I’m not yet sure how the dots connect, but could it be paired with something like this model?
Qwen Image Multiple Angles LoRA is an exquisitely trained LoRA!˚₊‧꒰ა
Keep character and scenes consistent, and flies the camera around! Open source got there! One of the best LoRAs I’ve come across lately pic.twitter.com/1mkmCpXgIY
Oh man, this parody of the messaging around AI-justified (?) price increases is 100% pitch perfect. (“It’s the corporate music that sends me into a rage.”)
My friend Bilawal got to sit down with VFX pioneer John Gaeta to discuss “A new language of perception,” Bullet Time, groundbreaking photogrammetry, the coming Big Bang/golden age of storytelling, chasing “a feeling of limitlessness,” and much more.
In this conversation:
— How Matrix VFX techniques became the prototypes for AI filmmaking tools, game engines, and AR/VR systems — How The Matrix team sourced PhD thesis films from university labs to invent new 3D capture techniques — Why “universal capture” from Matrix 2 & 3 was the precursor to modern volumetric video and 3D avatars — The Matrix 4 experiments with Unreal Engine that almost launched a transmedia universe based on The Animatrix — Why dystopian sci-fi becomes infrastructure (and what that means for AI safety) — Where John is building next: Escape.art and the future of interactive storytelling
I’m pleased to see that as promised back in May, Photoshop has added a “Dynamic Text” toggle that automatically resizes the size of the letters in each line to produce a visually “packed” look:
Results can be really cool, but because the model has no knowledge of the meaning and importance of each word, they can sometimes look pretty dumb. Here’s my canonical example, which visually emphasizes exactly the wrong thing:
I continue to want to see the best of both worlds, with a layout engine taking into account the meaning & thus visual importance of words—like what my team shipped last year:
I’m absolutely confident that this can be done. I mean, just look at the kind of complex layouts I was knocking out in Ideogram a year ago.
The missing ingredient is just the link between image layouts & editability—provided either by bitmap->native conversion (often hard, but doable in some cases), or by in-place editing (e.g. change “Merry Christmas” to “Happy New Year” on a sign, then regenerate the image using the same style & dimensions)—or both.
Bonus points go to the app & model that enable generation with transparency (for easy compositing), or conversion to vectors—or, again, ¿porque no los dos? 🙂
I recently shared a really helpful video from Jesús Ramirez that showed practical uses for each model inside Photoshop (e.g. text editing via Flux). Now here’s a direct comparison from Colin Smith, highlighting these strengths:
Flux: Realistic, detailed; doesn’t produce unwanted shifts in regions that should stay unchanged. Tends to maintain more of the original image, such as hair or background elements.
Nano Banana: Smooth & pleasing (if sometimes a bit “Disney”); good at following complex prompts. May be better at removing objects.
These specific examples are great, but I continue to wish for more standardized evals that would help produce objective measures across models. I’m investigating the state of the art there. More to share soon, I hope!
Improvements to imaging continues its breakneck pace, as engines evolve from “simple” text-to-image (which we considered miraculous just three years ago—and which I still kinda do, TBH) to understanding time & space.
Now Emu (see project page, code) can create entire multi-page/image narratives, turn 2D images into 3D worlds, and more. Check it out: