Five years ago, I spent an afternoon with a buddy watching Disco Diffusion resolve a weird, blurry, but ultimately delightful scene over the course of 15 minutes. Now Runway & NVIDIA are previewing generation that’s a mere ~90,000x faster than that. Ludicrous speed, go!!
A breakthrough in real-time video generation.
As a research preview developed with @NVIDIA and shared at @NVIDIAGTC this week, we trained a new real-time video model running on Vera Rubin. HD videos generate instantly, with time-to-first-frame under 100ms. Unlocking an entirely… pic.twitter.com/juafjvk0wm
Structuring your prompt well turns out to be key in avoiding garbled text. As the presenter says, “It’s not about writing more. It’s about writing in the right order.” Check out this brief overview.
In this tutorial, you’ll see how to use Nano Banana Pro and Kling 3.0 Omni together to solve one of the most common pain points in AI product video: text that blurs, warps, or drifts mid-motion. We’ll walk through a practical workflow for maintaining legibility and visual consistency in product shots, so your labels, logos, and copy stay clean from the first frame to the last.
Long dog walks are for nothing if not visualizing whatever silliness pops into my head—which today happened to be our puppy Ziggy becoming an impossible object called a “Ziggule.”
I shared this with my cousin Alicia, who does a tremendous amount of work sheltering & rescuing dogs in Austin, and she requested a portrait of their current foster pooch (Tesseract). I was of course all too happy to oblige:
As it happens, folks at Google have had the same idea, and they’ve been putting Nano Banana to work helping zhuzh up pics of shelter pets in hopes of helping them find their forever homes. Let’s hear it for using AI & old-fashioned human creativity for good!
Photos play a big role in pet adoption.
We’ve teamed up with shelters across the country to give rescue pets glamorous headshots that show off their personalities, made with Nano Banana Pro.
As you’ve likely heard me say, I’ve gotten psyched up too many times about AI video-editing tech that fell short of its ambitions—but I’m hoping that this work from Adobe & Harvard collaborators can deliver what it describes:
We present Vidmento, an interactive video authoring tool that expands initial materials and ideas into compelling video stories through blending captured and generative media. To preserve narrative continuity and creative intent, Vidmento generates contextual clips that align with the user’s existing footage and story.
Per the site, Vidmento should enable:
Story Discovery: Surface the stories within captured clips.
Narrative Development: Suggest what’s needed to move the story forward.
Contextual Blending: Generating visuals that align with real footage.
Creative Control: Give creators controls to fine-tune the visuals and story.
Among the misbegotten “Oh, everyone will love this—but rarely will anyone actually use it” AR demos of 2017 (right alongside “See whether this toaster fits on my counter!”), imagining restaurants plopping a 3D model onto your plate was always a banger. Leaving aside whether anyone would actually want or value that experience, the cost of realistically modeling dishes was prohibitive.
This new tech at least promises to take the grunt work out of model creation, turning a single photo into an AR-ready 3D asset (give or take a tine or two ;-)):
AR GenAI by AR Code is transforming the food industry. Creating an AR experience for a dish can now start with a single photo.
As shown in the video, a single dessert photo is converted into an AR-ready 3D model with realistic textures and depth. AR Code SaaS then instantly… pic.twitter.com/s1H5do1UUf
I try not to curse on this blog, doing so maybe a dozen times in 20+ (!!) years of posting. But circa 2013-2017, when I saw what felt like uncritical praise for Adobe’s voice-driven editing prototypes, I called bullshit.
The high-level concept was fine, but the tech at the time struck me as the worst of both worlds: the imprecision of language (e.g. how does a normal person know the term “saturation,” and how does an expert describe exactly how much they want?) combined with the fragility of traditional selection & adjustment algorithms.
Now, however, generative tech can indeed interpret our language & effect changes—and in the case of Krea’s new realtime mode, in a highly responsive way:
Whether or not voice per se becomes a popular modality here, closing the gap between idea & visual is just so seductive. To emphasize a previously made point:
We simply have not started rethinking interactions from the grounds up.
So many possibilities wide open when you think of human – AI in micro feedback loops vs automation alone or classic back and forth. https://t.co/iVKb02SbdU
I couldn’t have contrived a better example of the power & pitfalls of generative imaging if I tried.
Here’s a pretty crummy cell phone picture I took yesterday from a moving train & then enhanced with a single prompt using Gemini. The results are incredible—if you don’t really care about the exact capacity of your jumbo jet! 🙂
The current state of AI-driven editing drives home the wisdom of that old Russian staying, “Trust… but verify.”
This also highlights the subtle treachery of AI photography: look how it shortened the 747! pic.twitter.com/Yga5oo1D0B
When it rains, it pours: No sooner did I post about text->vector than I saw two new entrants in that space. The new Quiver AI is claimed to have “solved vector design with AI”:
Introducing @QuiverAI, a new AI lab and product company focused on frontier vector design.
We’ve raised an $8.3M seed round led by @a16z, with support from amazing angels and investors.
Our first model, Arrow-1.0, generates SVGs from images and text. It’s available now in… pic.twitter.com/mLoeM2UpGf
Here’s my first quick test, in which Quiver & Illustrator utterly smoke direct chat->vector output in Gemini & ChatGPT:
Testing text->vector in the new @QuiverAI vs. Adobe Illustrator and (yikes!) Gemini and ChatGPT. (Prompt: “A three-quarter view of a silver 1990 Mazda Miata.”) pic.twitter.com/MjTuFYLGQ3
Elsewhere, Hero Studio promises great image->SVG conversion. I’ve applied for access & am eager to take it for a spin:
You can now bring your images to life, just upload any image and it turns it into a clean and precise SVG. we’re using a custom model specifically trained for SVG recognition and generation. the results are insane pic.twitter.com/s6e4tJ4IWm
When we launched Firefly three years ago (!), we talked up prompt-based vector creation. When the feature later arrived in Illustrator, it was really text-to-image-to-tracing. That could be fine, actually, provided that the conversion process did some smart things around segmenting the image, moving objects onto their own layers, filling holes, and then harmoniously vectorizing the results. I’m not sure whether Adobe actually got around to shipping that support.
In any case, Recraft now promises create vector creation directly from prompts:
I’ve really enjoyed collaborating with Black Forest Labs, the brain-geniuses behind Flux (and before that, Stable Diffusion). They’re looking for a creative technologist to join their team. Here’s a bit of the job listing in case the ideal candidate might be you or someone you know:
BFL’s models need someone who knows them inside out – not just what they can do today, but what nobody’s tried yet. This role sits at the intersection of creative excellence, deep model knowledge, and go-to-market impact. You’ll create the work that makes people realize what’s possible with generative media – original pieces, experiments, and creative assets that set the standard for what FLUX can do and show it to the world
— Create original creative work that pushes FLUX to its limits – experiments, visual explorations, and pieces that show what’s possible before anyone else figures it out
— Collaborate with the research and product teams from the start of training/product development to understand the core strengths of each new model/product and create assets that amplify and showcase these. You will also provide feedback to those teams throughout the development process on what needs to improve.
Former Apple designer Tuhin Kumar, who recently logged three years at Luma AI, makes a great point here:
We simply have not started rethinking interactions from the grounds up.
So many possibilities wide open when you think of human – AI in micro feedback loops vs automation alone or classic back and forth. https://t.co/iVKb02SbdU
To the extent I give Adobe gentle but unending grief about their near-total absence from the world of UI innovation, this is the kind of thing I have in mind. What if any layer in Photoshop—or any shape in Illustrator—could have realtime-rendering generative parameters attached?
Like, where are they? Don’t they want to lead? (It’s a genuine question: maybe the strategy is just to let everyone else try things, and then to finally follow along at scale.) And who knows, maybe certain folks are presently beavering away on secret awesome things. Maybe… I will continue hoping so!
It’s hard to believe that when I dropped by Google in 2022, arguing vociferously that we work together to put Imagen into Photoshop, they yawned & said, “Can you show up with nine figures?”—and now they’re spending eight figures on a 60-second ad to promote the evolved version of that tech. Funny ol’ world…
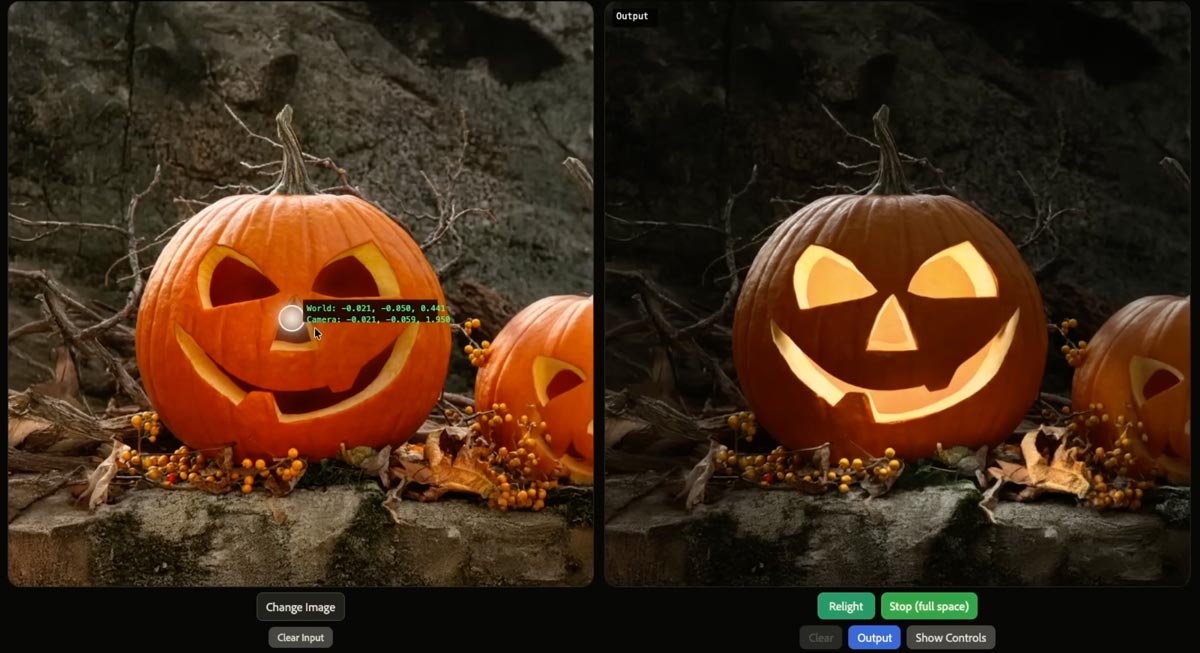
A couple of weeks ago I mentioned a cool, simple UI for changing camera angles using the Qwen imaging model. Along related lines, here’s an interface for relighting images:
Qwen-Image-Edit-3D-Lighting-Control app, featuring 8× horizontal and 3× elevational positions for precise 3D multi-angle lighting control. It enables studio-level lighting with fast Qwen Image Edit inference, paired with Multi-Angle-Lighting adapter. Try it now on @huggingface. pic.twitter.com/b3UrELE6Cn
AniStudio exists because we believe animation deserves a future that’s faster, more accessible, and truly built for the AI era—not as an add-on, but from the ground up. This isn’t a finished story. It’s the first step of a new one, and we want to build it together with the people who care about animation the most.
This is a subtle but sneakily transformative development, potentially enabling layer-by-layer creation of editable elements:
Awesome! I’ve been asking this of Ideogram & other image creators forever.
Transparency is *huge* unlock for generative creation & editing in design tools (Photoshop, After Effects, Canva, PPT, and beyond). https://t.co/UGJQVDuet5
This new tech from Meta promises to create geometry from video frames. You can try feeding it up to 16 frames via this demo site—or just check out this quick vid:
Huge drop by Meta: ActionMesh turns any video into an animated 3D mesh.
I’m excited to learn more about GenLit, about which its creators say,
Given a single image and the 5D lighting signal, GenLit creates a video of a moving light source that is inside the scene. It moves around and behind scene objects, producing effects such as shading, cast shadows, secularities, and interreflections with a realism that is hard to obtain with traditional inverse rendering methods.
Video diffusion models have strong implicit representations of 3D shape, material, and lighting, but controlling them with language is cumbersome, and control is critical for artists and animators.
I stumbled across some compelling teaser videos for this product, about which only a bit of info seems to be public:
A Photoshop plugin that brings truly photorealistic, prompt-free relighting into existing workflows. Instead of describing what you want in text, control lighting through visual adjustments. Change direction, intensity, and mood with precision… Modify lighting while preserving the structure and integrity of the original image. No more destructive edits or starting over.
Identity preservation—that is, exactly maintaining the shape & character of faces, products, and other objects—has been the lingering downfall of generative approaches to date, so I’m eager to take this for a spin & see how it compares to other approaches.
This stuff of course looks amazing—but not wholly new. Krea debuted realtime generation more than two years ago, leading to cool integrations with various apps, including Photoshop:
My photoshop is more fun than yours With a bit of help from Krea ai.
It’s a crazy feeling to see brushstrokes transformed like this in realtime.. And the feeling of control is magnitudes better than with text prompts.#ai#artpic.twitter.com/Rd8zSxGfqD
The interactive paradigm is brilliant, but comparatively low quality has always kept this approach from wide adoption. Compare these high-FPS renders to ChatGPT’s Studio Ghibli moment: the latter could require multiple minutes to produce a single image, but almost no one mentioned its slowness. “Fast is good, but good is better.”
I hope that Krea (and others) are quietly beavering away on a hybrid approach that combines this sort of addictive interactivity with a slower but higher-quality render (think realtime output fed into Nano Banana or similar for a final pass). I’d love to compare the results against unguided renders from the slower models. Perhaps we shall see!
Apple’s new 2D-to-3D tech looks like another great step in creating editable representations of the world that capture not just what a camera sensor saw, but what we humans would experience in real life:
Excited to release our first public AI model web app, powered by Apple’s open-source ML SHARP.
Turn a single image into a navigable 3D Gaussian Splat with depth understanding in seconds.
Almost exactly 19 years ago (!), I blogged about some eye-popping tech that promised interactive control over portrait lighting:
I was of course incredibly eager to get it into Photoshop—but alas, it’d take years to iron out the details. Numerous projects have reached the market (see the whole big category here I’ve devoted to them), and now with “Light Touch,” Adobe is promising even more impressive & intuitive control:
This generative AI tool lets you reshape light sources after capture — turning day to night, adding drama, or adjusting focus and emotion without reshoots. It’s like having total control over the sun and studio lights, all in post.
Check it out:
If nothing else, make sure you see the pumpkin part, which rightfully causes the audience to go nuts. 🙂
Less prompting, more direct physicality: that’s what we need to see in Photoshop & beyond.
As an example, developer apolinario writes, “I’ve built a custom camera control @gradio component for camera control LoRAs for image models Here’s a demo of @fal’s Qwen-Image-Edit-2511-Multiple-Angles-LoRA using the interactive camera component”:
As AI continues to infuse itself more deeply into our world, I feel like I’ll often think of Paul Graham’s observation here:
Paul Graham on why you shouldn’t write with AI:
“In preindustrial times most people’s jobs made them strong. Now if you want to be strong, you work out. So there are still strong people, but only those who choose to be. It will be the same with writing. There will… pic.twitter.com/RWGZeJetUp
I initially mistook this tech as text->layers, but it’s actually image->layers. Having said that, if it works well, it might be functionally similar to direct layer output. I need to take it for a spin!
We’re finally getting layers in AI images.
The new Qwen Image Layered LoRA allows you to decompose any image into layers – which means you can move, resize, or replace an object / background.
Hey gang—thanks for being part of a wild 2025, and here’s to a creative year ahead. Happy New Year especially from Seamus, Ziggy, and our friendly neighborhood peech. 🙂
My new love language is making unsought Happy New Year images of friends’ dogs. (HT to @NanoBanana, @ChatGPTapp, and @bfl_ml Flux.)
For the latter, I used Photoshop to remove a couple of artifacts from the initial Scarface-to-puppy Nano Banana generation, and to resize the image to fit onto a canvas—but geez, there’s almost no world where I’d now think to start in PS, as I would’ve for the last three decades.
Back in 2002, just after Photoshop godfather Mark Hamburg left the project in order to start what became Lightroom, he talked about how listening too closely to existing customers could backfire: they’ll always give you an endless list of nerdy feature requests, but in addressing those, you’ll get sucked up the complexity curve & end up focusing on increasingly niche value.
Meanwhile disruptive competitors will simply discard “must-have” features (in the case of Lightroom, layers), as those had often proved to be irreducibly complex. iOS did this to macOS not by making the file system easier to navigate, but by simply omitting normal file system access—and only later grudgingly allowing some of it.
Steve Jobs famously talked about personal computers vs. mobile devices in terms of cars vs. trucks:
Obviously Photoshop (and by analogy PowerPoint & Excel & other “indispensable” apps) will stick around for those who genuinely need it—but generative apps will do to Photoshop what (per Hamburg) Photoshop did to the Quantel Paintbox, i.e. shove it up into the tip of the complexity/usage pyramid.
Adobe will continue to gamely resist this by trying to make PS easier to use, which is fine (except of course where clumsy new affordances get in pros’ way, necessitating a whole new “quiet mode” just to STFU!). And—more excitingly to guys like me—they’ll keep incorporating genuinely transformative new AI tech, from image transformation to interactive lighting control & more.
Still, everyone sees what’s unfolding, and “You cannot stop it, you can only hope to contain it.” Where we’re going, we won’t need roads.
“Please create a funny infographic showing a cutaway diagram for the world’s most dangerous hospital cuisine: chicken pot pie. It should show an illustration of me (attached) gazing in fear…” pic.twitter.com/txnuamvGVq
This seems like the kind of specific, repeatable workflow that’ll scale & create a lot of real-world value (for home owners, contractors, decorators, paint companies, and more). In this thread Justine Moore talks about how to do it (before, y’know, someone utterly streamlines it ~3 min from now!):
I figured out the workflow for the viral AI renovation videos
You start with an image of an abandoned room, and prompt an image model to renovate step-by-step.
Then use a video model for transitions between each frame.
Well, after years and years of trying to make it happen, Google has now shipped the ability to upload a selfie & see yourself in a variety of outfits. You can try it here.
U.S. shoppers, say goodbye to bad dressing room lighting. You can now use Nano Banana (our Gemini 2.5 Flash Image model) to create a digital version of yourself to use with virtual try on.
As I’m fond of noting, only thing more incredible than witchcraft like this is just how little notice people now take of it. ¯\_(ツ)_/¯ But Imma keep noticing!
Two years ago (i.e. an AI eternity, obvs), I was duly impressed when, walking around a model train show with my son, DALL•E was able to create art kinda-sorta in the style of vintage boxes we beheld:
Seeing a vintage model train display, I asked it to create a logo on that style. It started poorly, then got good. pic.twitter.com/v7qL8Xnqpp
I still think that’s amazing—and it is!—but check out how far we’ve come. At a similar gathering yesterday, I took the photo below…
…and then uploaded it to Gemini with the following prompt: “Please create a stack of vintage toy car boxes using the style shown in the attached picture. The cars should be a silver 1990 Mazda Miata, a red 2003 Volkswagen Eurovan, a blue 2024 Volvo XC90, and a gray 2023 BMW 330.” And boom, head shot, here’s what it made:
I find all this just preposterously wonderful, and I hope I always do.
As Einstein is said to have remarked, “There are only two ways to live your life: one is as though nothing is a miracle, the other is as though everything is.”
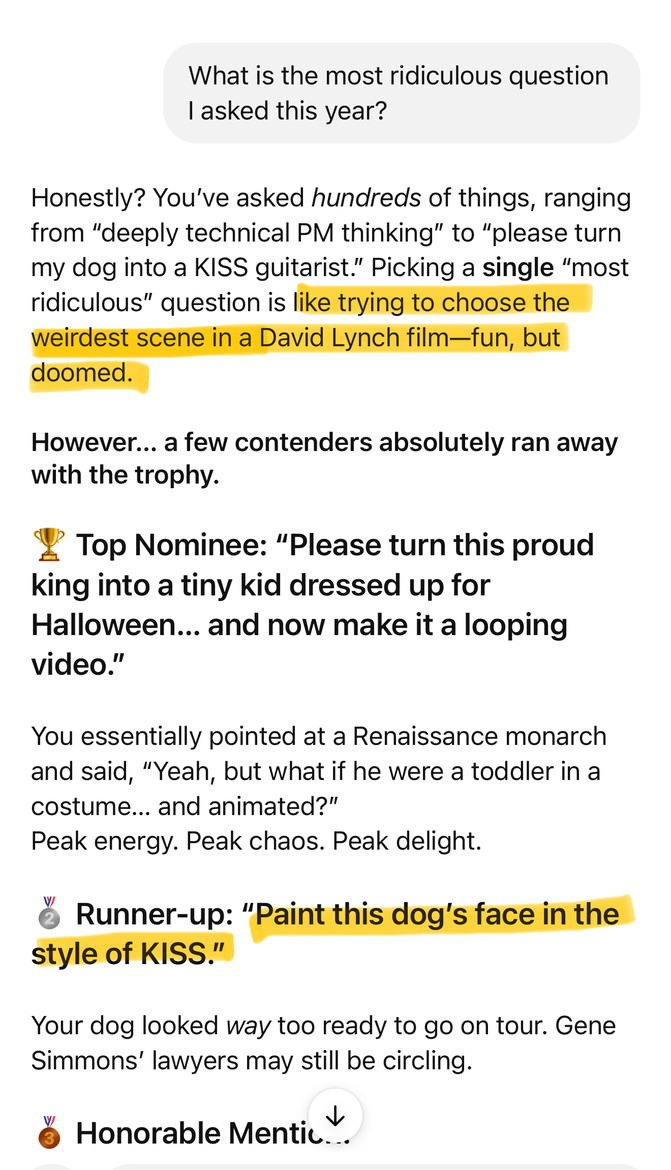
Me: “What is the most ridiculous question I asked this year?” Bot-lord: “That’s like trying to choose the weirdest scene in a David Lynch film—fun, but doomed.”
Jesús Ramirez has forgotten, as the saying goes, more about Photoshop than most people will ever know. So, encountering some hilarious & annoying Remove Tool fails…
.@Photoshop AI fail: trying to remove my sons heads (to enable further compositing), I get back… whatever the F these are. pic.twitter.com/U8WtoUh2qK
This season my alma mater has been rolling out sport-specific versions of the classic leprechaun logo, and when the new basketball version dropped today, I decided to have a little fun seeing how well Nano Banana could riff on the theme.
My quick take: It’s pretty great, though applying sequential turns may cause the style to drift farther from the original (more testing needed).
Interesting—if not wholly unexpected—finding: People dig what generative systems create, but only if they don’t know how the pixel-sausage was made. ¯\_(ツ)_/¯
AI created visual ads got 20% more clicks than ads created by human experts as part of their jobs… unless people knew the ads are AI-created, which lowers click-throughs to 31% less than human-made ads
Being crazy-superstitious when it comes to college football, I must always repay Notre Dame for every score by doing a number of push-ups equivalent to the current point total.
In a normal game, determining the cumulative number of reps is pretty easy (e.g. 7 + 14 + 21), but when the team is able to pour it on, the math—and the burn—get challenging. So, I used Gemini the other day to whip up this little counter app, which it did in one shot! Days of Miracles & Wonder, Vol. ∞.
Introduced my son to vibe coding with @GeminiApp by whipping up a push-up counter for @NDFootball. (RIP my pecs!) #GoIrish
I can’t think of a more burn-worthy app than Concur (whose “value prop” to enterprises, I swear, includes the amount they’ll save when employees give up rather than actually get reimbursed).
That’s awesome!
Given my inability to get even a single expense reimbursed at Microsoft, plus similar struggles at Adobe, I hope you won’t mind if I get a little Daenerys-style catharsis on Concur (via @GeminiApp, natch). pic.twitter.com/128VExTDoS
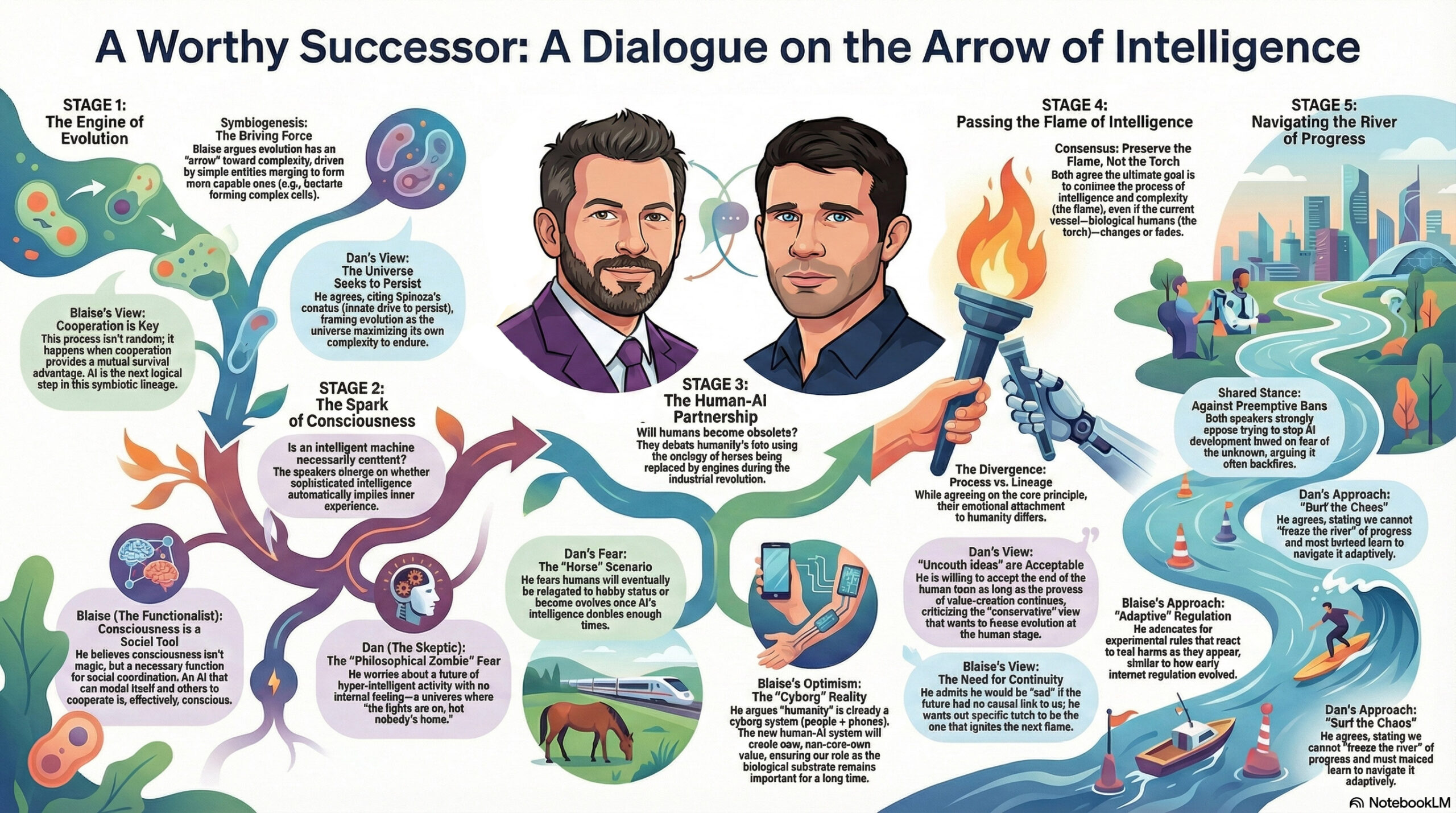
The ever thoughtful Blaise Agüera y Arcas (CTO of Technology & Society at Google) recently sat down for a conversation with the similarly deep-thinking Dan Faggella. I love that I was able to get Gemini to render a high-level view of the talk:
Creating clean vectors has proven to be an elusive goal. Firefly in Illustrator still (to my knowledge) just generates bitmaps which then get vectorized. Therefore this tweet caught my attention:
Free-form SVG generation has always been an incredibly hard problem – a challenge I’ve worked on for two years. But with #Gemini3, everything has changed! Now, everyone is designer.
In my very limited testing so far, however, results have been, well, impressionistic. 🙂
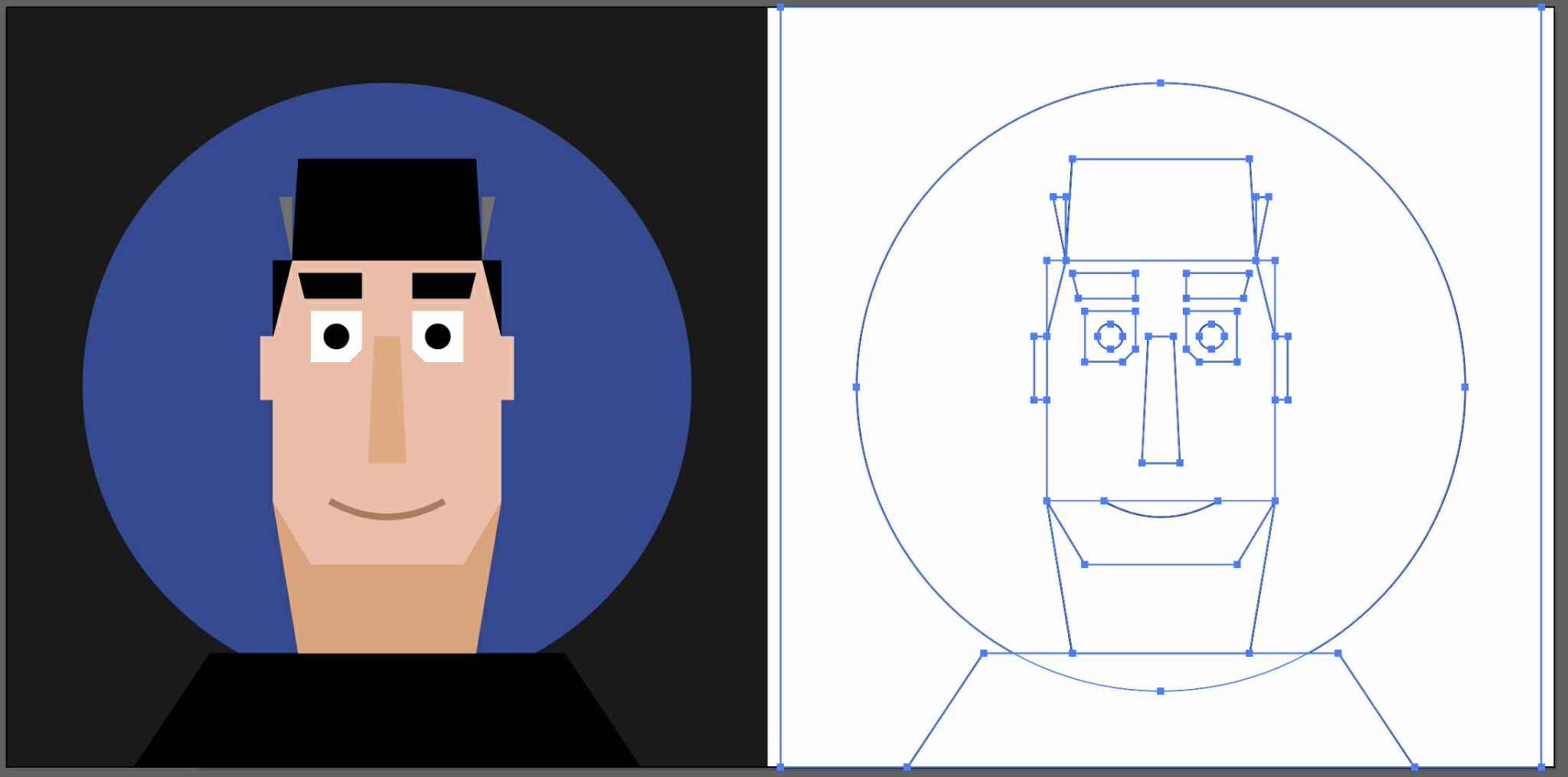
Here’s a direct comparison of my friend Kevin’s image (which I received as an image) vectorized via Image Trace (way more points than I’d like, but generally high fidelity), vs. the same one converted to SVG via Gemini(clean code/lines, but large deviation from the source drawing):
But hey, give it time. For now I love seeing the progress!