The video below shipped on VHS with the very first version of Adobe Illustrator. Adobe CEO & Illustrator developer John Warnock demonstrated the new product in a single one-hour take. He was certainly qualified, being one of the four developers whose names were listed on the splash screen!
How lucky it was for the world that a brilliant graphics engineer (John) married a graphic designer (Marva Warnock) who could provide constant input as this groundbreaking app took shape.
If you’re interested in more of the app’s rich history, check out The Adobe Illustrator Story:
The Corridor Crew has been banging on Stable Diffusion & Google’s new DreamBooth tech (see previous) that enables training the model to understand a specific concept—e.g. one person’s face. Here they’ve trained it using a few photos of team member Sam Gorski, then inserted him into various genres:
From there they trained up models for various guys at the shop, then created an illustrated fantasy narrative. Just totally incredible, and their sheer exuberance makes the making-of pretty entertaining:
The makers of this new search engine say they’re already serving more than 200,000 images/day & growing rapidly. Per this article, “It’s a massive collection of over 5 million Stable Diffusion images including its text prompts.” Just get ready to see some… interesting art (?). 🙃
'Consonance' is my project that explores how AI interprets the spoken word. This is an excerpt from a James Joyce novel. I use his words exactly for the prompt, in the style of artist John Lavery. Funded by @futurescreensni A collaboration with @HeaneyCentre + Armchair & Rocket pic.twitter.com/8sGgipjZeb
“Shoon is a recently released side scrolling shmup,” says Vice, “that is fairly unremarkable, except for one quirk: it’s made entirely with art created by Midjourney, an AI system that generates images from text prompts written by users.’ Check out the results:
Magdalena Bay has shared a new Felix Geen directed video for “Dreamcatching.” The clip, multi-dimensional explored through cutting-edge AI technology and GAN artwork, combined with VQGAN+CLIP, is a technique that utilizes a collection of neural networks that work in unison to generate images based on input text and/or images.
Creative director Wes Phelan shared this charming little summary of how he creates kids’ books & games using DALL•E, including their newly launched outpainting support:
We ask: how can we use language-guided models to turn our cat into a painting, or imagine a new product based on our favorite toy? Here we present a simple approach that allows such creative freedom.
Using only 3-5 images of a user-provided concept, like an object or a style, we learn to represent it through new “words” in the embedding space of a frozen text-to-image model. These “words” can be composed into natural language sentences, guiding personalized creation in an intuitive way.
Many years ago (nearly 10!), when I was in the thick of making up bedtime stories every night, I wished aloud for an app that would help do the following:
Record you telling your kids bedtime stories (maybe after prompting you just before bedtime)
Transcribe the text
Organize the sound & text files (into a book, journal, and/or timeline layout)
Add photos, illustrations, and links.
Share from the journal to a blog, Tumblr, etc.
I was never in a position to build it, but seeing this fusion of kid art + AI makes me hope again:
With #stablediffusion img2img, I can help bring my 4yr old’s sketches to life.
Elsewhere, After Effects ninja Paul Trillo is back at it with some amazing video-meets-DALL•E-inpainting work:
AI fashion show using dall-e to generate hundreds of outfits of the day after tomorrow. An interesting way to brainstorm costume and fashion design ideas.
I mentioned Meta Research’s DALL•E-like Make-A-Scene tech when it debuted recently, but I couldn’t directly share their short overview vid. Here’s a quick look at how various artists have been putting the system to work, notably via hand-drawn cues that guide image synthesis:
This new tech from Facebook Meta one-ups DALL•E et al by offering more localized control over where elements are placed:
Excited to announce Make-A-Scene, our latest research tool Mark Zuckerberg just shared. Make-A-Scene is an exploratory concept that gives creative control to anyone, artists & non-artists alike to use both text & sketches to guide AI image generation: https://t.co/p9HNFy3VeYpic.twitter.com/Ir5U4IvikV
We found that the image generated from both text and sketch was almost always (99.54 percent of the time) rated as better aligned with the original sketch. It was often (66.3 percent of the time) more aligned with the text prompt too. This demonstrates that Make-A-Scene generations are indeed faithful to a person’s vision communicated via the sketch.
The technology’s ability not only to synthesize new content, but to match it to context, blows my mind. Check out this thread showing the results of filling in the gap in a simple cat drawing via various prompts. Some of my favorites are below:
Also, look at what it can build out around just a small sample image plus a text prompt (a chef in a sushi restaurant); just look at it!
Hard on the heels of OpenAI revealing DALL•E 2 last month, Google has announced Imagen, promising “unprecedented photorealism × deep level of language understanding.” Unlike DALL•E, it’s not yet available via a demo, but the sample images (below) are impressive.
I’m slightly amused to see Google flexing on DALL•E by highlighting Imagen’s strengths in figuring out spatial arrangements & coherent text (places where DALL•E sometimes currently struggles). The site claims that human evaluators rate Imagen output more highly than what comes from competitors (e.g. MidJourney).
I couldn’t be more excited about these developments—most particularly to figure out how such systems can enable amazing things in concert with Adobe tools & users.
I’ve long admired President Obama’s official portrait, but I haven’t known much about Kehinde Wiley. I enjoyed this brief peek into his painting process:
Last year I took my then-11yo son Henry (aka my astromech droid) on a 2000-mile “Miodyssey” down Route 66 in my dad’s vintage Miata. It was a great way to see the country (see more pics & posts than you might ever want), and despite the tight quarters we managed not to kill one another—or to get slain by Anton Chigurh in an especially murdery Texas town (but that’s another story!).
Heh—I love this kind of silly mashup. (And now I want to see what kind of things DALL•E would dream up for prompts like “medieval grotesque Burger King logo.”)
There’s no way this is real, is there?! I think it must use NFW technology (No F’ing Way), augmented with a side of LOL WTAF. 😛
Here’s an NYT video showing the system in action:
The NYT article offers a concise, approachable description of how the approach works:
A neural network learns skills by analyzing large amounts of data. By pinpointing patterns in thousands of avocado photos, for example, it can learn to recognize an avocado. DALL-E looks for patterns as it analyzes millions of digital images as well as text captions that describe what each image depicts. In this way, it learns to recognize the links between the images and the words.
When someone describes an image for DALL-E, it generates a set of key features that this image might include. One feature might be the line at the edge of a trumpet. Another might be the curve at the top of a teddy bear’s ear.
Then, a second neural network, called a diffusion model, creates the image and generates the pixels needed to realize these features. The latest version of DALL-E, unveiled on Wednesday with a new research paper describing the system, generates high-resolution images that in many cases look like photos.
Though DALL-E often fails to understand what someone has described and sometimes mangles the image it produces, OpenAI continues to improve the technology. Researchers can often refine the skills of a neural network by feeding it even larger amounts of data.
“Lost your keys? Lost your job?” asks illustrator Don Moyer. “Look at the bright side. At least you’re not plagued by pterodactyls, pursued by giant robots, or pestered by zombie poodles. Life is good!”
I find this project (Kickstarting now) pretty charming:
Adam Buxton recorded a conversation with his 5-year-old daughter discussing her thoughts on Princess Leia’s famous slave outfit. She is hilarious by herself but when he got The Brothers McLeod to animate her words, it all turned into pure comedic gold.
I’m not sure who captured this image (conservationist Beverly Joubert, maybe?), or whether it’s indeed the National Geographic Picture of The Year, but it’s stunning no matter what. Take a close look:
National Geographic Picture of The Year. Black images are shadows of zebras. Zoom in and you will see zebras. pic.twitter.com/6dwnJ0uBSC
And that example, curiously, seems way more technically & aesthetically sophisticated than the bulk of what I see coming from the “NFT art” world. I really enjoyed this explication of why so much of such content seems like cynical horseshit—sometimes even literally:
Forty months in the making, “Pass the Ball” is a delightful and eccentric example of the creative possibilities of collaboration […] Each scenario was created by one of 40 animators around the world, who, as the title suggests, “pass the ball” to the next person, resulting in a varied display of styles and techniques from stop-motion to digital.
Researchers at NVIDIA & Case Western Reserve University have developed an algorithm that can distinguish different painters’ brush strokes “at the bristle level”:
Extracting topographical data from a surface with an optical profiler, the researchers scanned 12 paintings of the same scene, painted with identical materials, but by four different artists. Sampling small square patches of the art, approximately 5 to 15 mm, the optical profiler detects and logs minute changes on a surface, which can be attributed to how someone holds and uses a paintbrush.
They then trained an ensemble of convolutional neural networks to find patterns in the small patches, sampling between 160 to 1,440 patches for each of the artists. Using NVIDIA GPUs with cuDNN-accelerated deep learning frameworks, the algorithm matches the samples back to a single painter.
The team tested the algorithm against 180 patches of an artist’s painting, matching the samples back to a painter at about 95% accuracy.
Possibly my #1 reason to want to return to in-person work: getting to use apps like this (see previous overview) on a suitably configured workstation (which I lack at home).
Sundance Grand Jury Prize winner FLEE tells the story of Amin Nawabi as he grapples with a painful secret he has kept hidden for 20 years, one that threatens to derail the life he has built for himself and his soon to be husband. Recounted mostly through animation to director Jonas Poher Rasmussen, he tells for the first time the story of his extraordinary journey as a child refugee from Afghanistan.
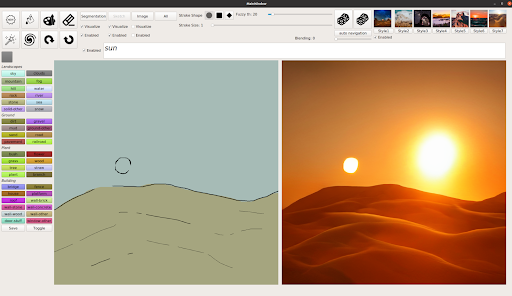
Rather than needing to draw out every element of an imagined scene, users can enter a brief phrase to quickly generate the key features and theme of an image, such as a snow-capped mountain range. This starting point can then be customized with sketches to make a specific mountain taller or add a couple trees in the foreground, or clouds in the sky.
It doesn’t just create realistic images — artists can also use the demo to depict otherworldly landscapes.
Perhaps a bit shockingly, I’ve somehow been only glancingly familiar with the artist’s career, and I really enjoyed this segment—including a quick visual tour spanning his first daily creation through the 2-minute piece he made before going to the hospital for the birth of his child (!), to the work he sold on Tuesday for nearly $30 million (!!).
Type the name of something (e.g. “beautiful flowers”), then use a brush to specify where you want it applied. Here, just watch this demo:
The first project is ProsePainter, an interactive tool to “paint with words.” It incorporates guidable text-to-image generation into a traditional digital painting interface.
Today we are introducing Pet Portraits, a way for your dog, cat, fish, bird, reptile, horse, or rabbit to discover their very own art doubles among tens of thousands of works from partner institutions around the world. Your animal companion could be matched with ancient Egyptian figurines, vibrant Mexican street art, serene Chinese watercolors, and more. Just open the rainbow camera tab in the free Google Arts & Culture app for Android and iOS to get started and find out if your pet’s look-alikes are as fun as some of our favorite animal companions and their matches.
By analyzing various artists’ distinctive treatment of facial geometry, researchers in Israel devised a way to render images with both their painterly styles (brush strokes, texture, palette, etc.) and shape. Here’s a great six-minute overview:
10 years ago we put a totally gratuitous (but fun!) 3D view of the layers stack into Photoshop Touch. You couldn’t actually edit in that mode, but people loved seeing their 2D layers with 3D parallax.
More recently apps are endeavoring to turn 2D photos into 3D canvases via depth analysis (see recent Adobe research), object segmentation, etc. That is, of course, an extension of what we had in mind when adding 3D to Photoshop back in 2007 (!)—but depth capture & extrapolation weren’t widely available, and it proved too difficult to shoehorn everything into the PS editing model.
Now Mental Canvas promises to enable some truly deep expressivity:
I do wonder how many people could put it to good use. (Drawing well is hard; drawing well in 3D…?) I Want To Believe… It’ll be cool to see where this goes.
I plan to highlight several of the individual technologies & try to add whatever interesting context I can. In the meantime, if you want the whole shebang, have at it!
Extending Illustrator and Photoshop to the web (beta) will help you share creative work from the Illustrator and Photoshop desktop and iPad apps for commenting. Your collaborators can open and view your work in the browser and provide feedback. You’ll also be able to make basic edits without having to download or launch the apps.
Creative Cloud Spaces (beta) are a shared place that brings content and context together, where everyone on your team can access and organize files, libraries, and links in a centralized location.
Creative Cloud Canvas (beta) is a new surface where you and your team can display and visualize creative work to review with collaborators and explore ideas together, all in real-time and in the browser.
Adobe extends Photoshop to the web for sharing, reviewing, and light editing of Photoshop cloud documents (.psdc). Collaborators can open and view your work in the browser, provide feedback, and make basic edits without downloading the app.
Photoshop on the web beta features are now available for testing and feedback. For help, please visit the Adobe Photoshop beta community.
Let’s say you dig AR but want to, y’know, actually create instead of just painting by numbers (just yielding whatever some filter maker deigns to provide). In that case, my friend, you’ll want to check out this guidance from animator/designer/musician/Renaissance man Dave Werner.
0:00 Intro 1:27 Character Animator Setup 7:38 After Effects Motion Tracking 14:14 After Effects Color Matching 17:35 Outro (w/ surprise cameo)






























{kind=link}